The Data View: Editing OntoLex-Lemon lexicons
Intro
This section describes the OntoLex-Lemon editing functionalities available in VocBench. We will go through the set of functionalities as they appear in the various elements of the user interface.
Please note that: as of version 4.0 and 5.0 of VocBench, the settings for the combinations of other models (RDFS, OWL or SKOS) with Ontolex as a lexicalization model in a project need still improvement. As a consequence, if you need to use Ontolex-Lemon at any extent in your project (from simply lexicalizing an existing ontology with lexical entries from an existing lexicon to building from scratch all of these resources we strongly suggest to choose Ontolex-Lemon both as the (semantic) model of the project and the lexical model.
The Various Sections in OntoLex Projects
OntoLex Projects offer 8 sections for managing different kind of resources. These include sections that we have already described in the manual page on OWL Editing and SKOS Editing, so here we will discuss the Lexicon and Lexical Entry Sections peculiar to OntoLex-Lemon.
When editing an OntoLex-Lemon lexicon, the landing page for the Data View is the Lexicon Section.
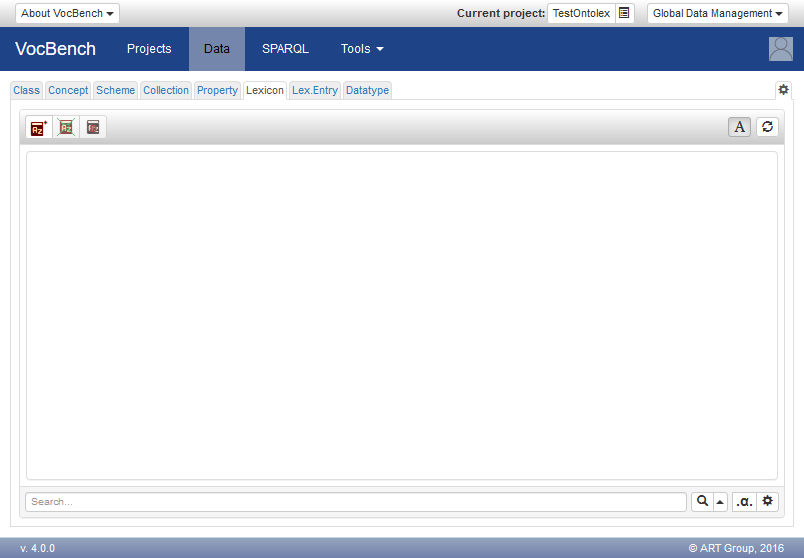
The Lexicon Section
The Lexicon Section (as of all the data section) is composed of two main areas: the structure on the left, and the resource view on the right. However, differently from other resources (e.g. classes, properties or concepts), the structure page offers a simple list, and not a tree as lime:Lexicons have no taxonomic relation among them. Quoting the definition of lime:Lexicon: "A lexicon is a collection of lexical entries for a particular language or domain".
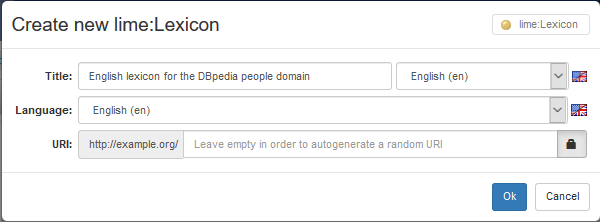
The Lexicon section allows to create and destroy Lexicons. When the usual + button is clicked, a form allows the user to prompt the lexicon information. The form is composed of the following elements:
- Title: when a lexicon is created, a title will be attached to it. The title will be generated with the prompted text and bound to the lexicon with the dcterms:title property
- Language: the natural language that characterizes the lexicon being created
- URI: the URI for the lexicon can be manually defined by the user, or a random one can be generated. It is possible to specify the pattern to be used for random ID generation (see advanced manual). In case of manual prompt, the user may adopt the default namespace defined for the dataset and just create the local name, or can specify the entire URI by unsetting the lock icon on the right of the URI textfield
- lime:Lexicon icon on the top-right corner of the form: lexicons are created by instantiating the lime:Lexicon class. Currently, it is not possible for the user to specialize this class and create instances of the specialized class.
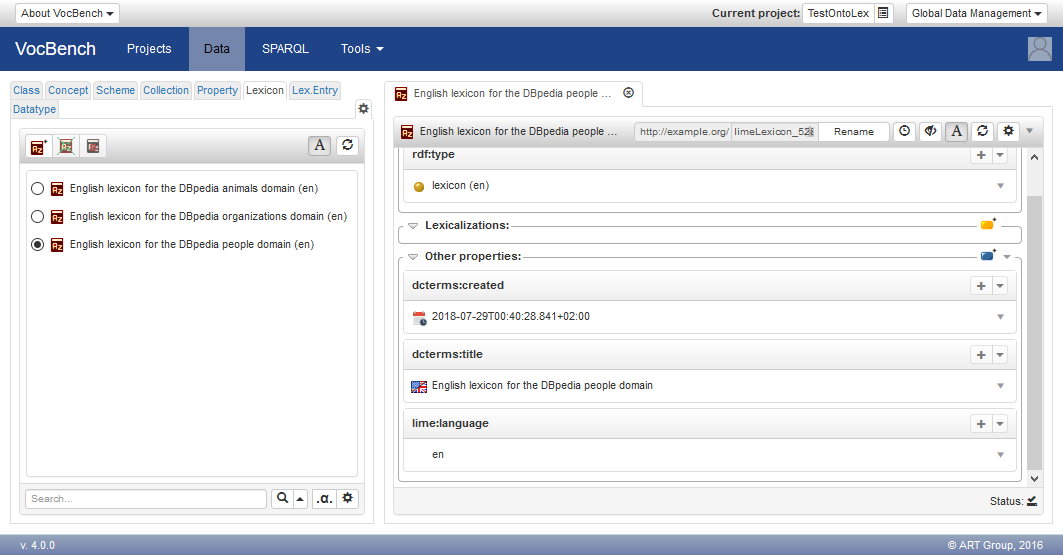
Once one or more schemes are created, they will appear as a list in the structure section. Note that the radio buttons on the left of the lexicons allow to select one of them. This selection will affect the Lexical Entry Section.
The Lexical Entry Section
The Lexical Entry Section is composed of two main areas as all other sections. The structure on the left, and the resource view on the right. The structure offers a list-view very similar to the one in the Lexicon section, though here the lexical entries are subdivided alphabetically. A dropdown menu between the toolbar and the list allows switching to a different letter of the alphabet.
As we anticipated in the previous section, the list view is affected by the selection of a lexicon performed on the Lexicon section. Only those lexical entries belonging to the selected lexicon will be shown on the list. Most of the following examples are based on the data from the lemon lexica for DBpedia.
The subdivision of the lexical entries by first letter is similar to the organization of alphabetically indexed printed dictionaries. It should help the user navigate a potentially long list of lexical entries. Additionally, the user can find a lexical entry through the search field on the bottom of the structure: the selection of a result causes the automatic switch to the right letter of the alphabet.
The alphabetic indexing of lexical entries is also meant to reduce the number of lexical entries that should be retrieved and then displayed in the UI: this optimization can be very important when working with large lexicons. In some circumstances, a single alphabetic index may not sufficient, because the number of matching entries is too high. The gear (![]() ) above the list can be clicked to reveal a dialog that allows to customize the view. In particular, it is possible to switch between the "Index based" and the "Search based" visualization modes. The former is enabled by default, and it can be configured by choosing between using just one or two letters as index. A longer index has be shown to be adequate for browsing very large lexicons such as the Open Multilingual Wordnet. The "search based" visualization mode offers an alternative in which the list is only populated with the results of a search. This mode has been used with the English portion of the IATE terminology.
) above the list can be clicked to reveal a dialog that allows to customize the view. In particular, it is possible to switch between the "Index based" and the "Search based" visualization modes. The former is enabled by default, and it can be configured by choosing between using just one or two letters as index. A longer index has be shown to be adequate for browsing very large lexicons such as the Open Multilingual Wordnet. The "search based" visualization mode offers an alternative in which the list is only populated with the results of a search. This mode has been used with the English portion of the IATE terminology.
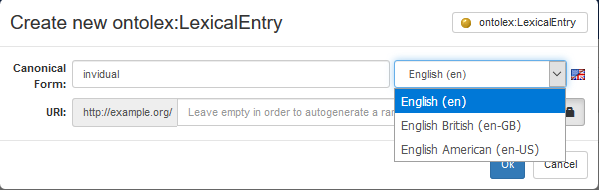
The Lexical Entry Section also allows to create and delete lexical entries. When usual button + is clicked, a form allows the user to supply the necessary information about the lexical entry. The form is composed of the following elements:
- Canonical form: the written representation of the canonical/dictionary form of the lexical entry. The allowed natural languages are constrained by the language of the lexicon that will contain the new lexical entry.
- URI: the URI for the lexicon can be manually defined by the user, or a random one can be generated. It is possible to specify the pattern to be used for random ID generation (see advanced manual). In case of manual prompt, the user may adopt the default namespace defined for the dataset and just create the local name, or can specify the entire URI by unsetting the lock icon on the right of the URI textfield
- ontolex:LexicalEntry icon on the top-right corner of the form: lexical entries are created by instantiating the ontolex:LexicalEntry class. However, it is possible for the user to specialize this class and create instances of the specialized class. For example, one may use the specializations defined by the OntoLex-Lemon model: ontolex:Word, ontolex:MultiWordExpression and ontolex:Affix.
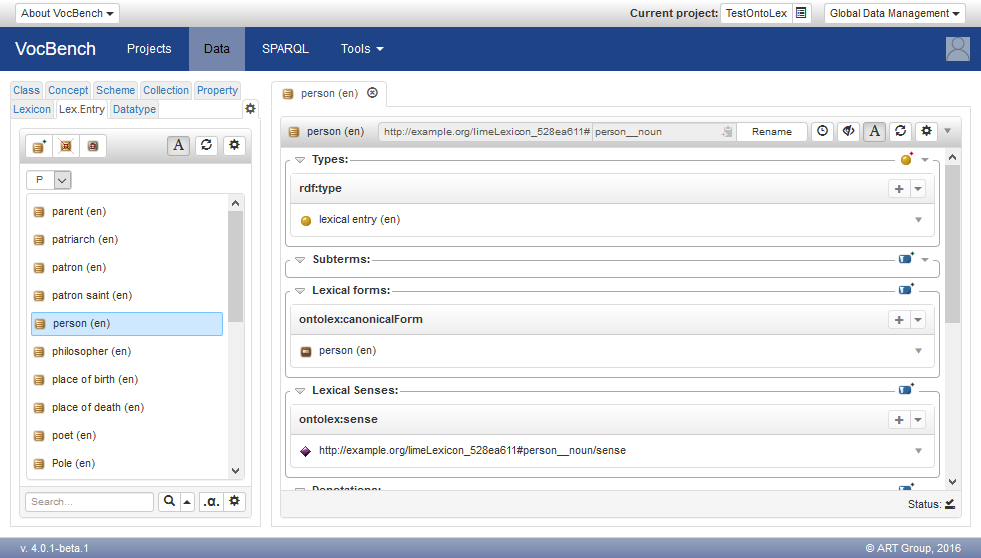
The Lexical-Entry-view
The resource-view for lexical entry (or, simply, lexical-entry-view) is divided into a few sections listing the following information:
- Types: the lexical entries are usually of type ontolex:LexicalEntry (or one of its subclasses ontolex:Word, ontolex:MultiWordExpression and ontolex:Affix). However, some lexical entries may have further types from external linguistic ontologies (e.g. lexinfo:NounPhrase for multiword expressions headed by a noun).
- Subterms: this section lists some of the lexical entries a compound lexical entry is made of.
- Lexical forms: this section lists the grammatical form variants of the lexical entry (ontolex:lexicalForm), subdivided by typology (usually, a ontolex:canonicalForm and zero or more ontolex:otherForms).
- Lexical Senses: this section lists the senses (ontolex:sense) of the lexical entry. Each sense is an object (of class ontolex:LexicalSense) that represents the binding of a lexical entry to a resource in a lexicalized dataset, formally describing the meaning of the lexical entry.
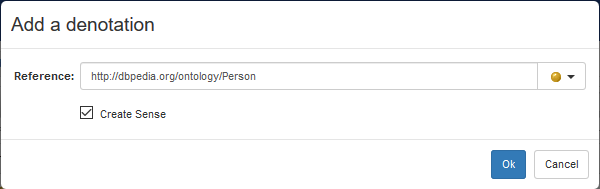
- Denotations: the set of resources in a lexicalized dataset denoted of by the lexical entry. These correspond to the objects of the property ontolex:denotes (or a subproperty of its).
- Evoked Lexical Concepts: the set of lexical concepts (ontolex:LexicalConcept) evoked by the lexical entry. These correspond to the objects of the property ontolex:evokes (or a subproperty of its).
- Constituents: each of the elements that compose the lexical entry. In case of a compound lexical entry, these correspond to its tokens.
- RDFS members: this sections lists the values for the rdfs:member property and its subproperties, such as rdf:_1, rdf:_2, etc. The properties rdf:_N can be used to represent the order of the constituents of the lexical entry.
- Properties: any triple not falling in any of the sections above, is reported in this section
The addition of a form is informed by the contextual information associated with the lexical entry, so that it is only possible to select a natural language compatible to the one declared in the lexicon a given lexical entry belongs to. In fact, the system first looks at the language declared in the lexical entry, which should match the one declared in the lexicon.
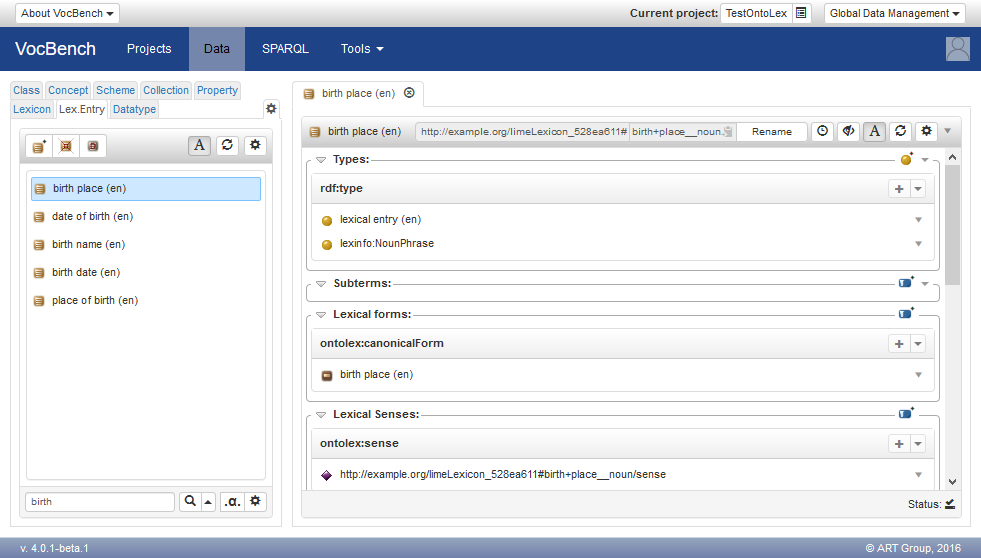
It is worth to mention the fact that the content of the RDFS members section is used by system to display the constituents in the intended order.
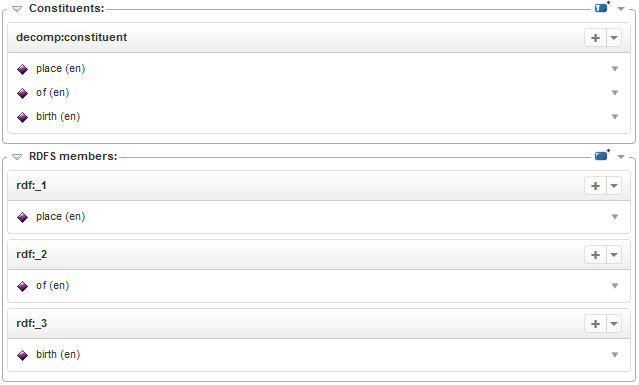
Individual constituents should not be added or removed individually, nor should RDFS members be edited directly. Actually, the decomposition of a lexical entry should be edited as a whole: the new decomposition would automatically replace the existing one. If the user indicated a compound lexical entry as a constituent of the lexical entry, the system does the following: the compound is used as subterm, while its constituents are in turn used in the decomposition of the lexical entry.
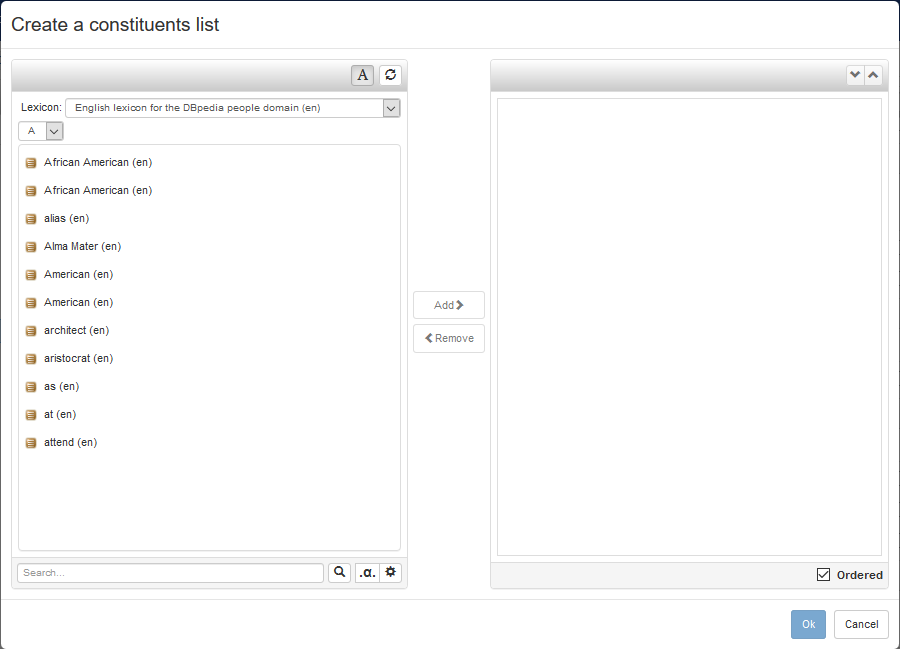
Another interesting observation is that the Lexical Senses and Denotations sections are related from the point of view of the OntoLex-Lemon model, as they represent the same information conceptually, that is to say the binding of lexical entries to resources in the lexicalized dataset. The Lexical Senses Section lists the reified version of the binding, represented by a ontolex:LexicalSense object relating the two entities. Differently, the Denotations Sections lists the bindings realized as a mere triple with predicate ontolex:denotes. The system tries to maintain the two sections in sync by doing the following:
- in the dialog for the addition of a sense (respectively, a denotation), the system suggests to create the plain version (respectively, the sense)
- the deletion of a sense (respectively, a denotation) causes the deletion of the denotation (respectively, the sense)
In fact, the system manages the creation and the deletion, respectively, of slightly more triples, since it takes into consideration the inverse properties defined by the OntoLex-Lemon model. As an example, when adding a denotation to a lexical entry, the system adds to the denoted resource the inverse properties relating it to the denoting lexical entry (only if the denoted resource is locally defined in the current project).
The Form-view
The forms of lexical entries are modeled in OntoLex-Lemon as resources of type ontolex:Form. Consequently, it is possible to double-click on them (e.g. within the Lexical Forms Section of a lexical-entry-view) and open their resource view. The resource-view for a form (or, simply, form-view) is divided into a few sections listing the following information:
- Types: the forms are usually of type ontolex:Form.
- Form Representations: this section lists the representations (ontolex:representation and its subproperties) of the form, subdivided by typology (usually, ontolex:writtenRep and ontolex:phoneticRep).
- Properties: any triple not falling in any of the sections above, is reported in this section
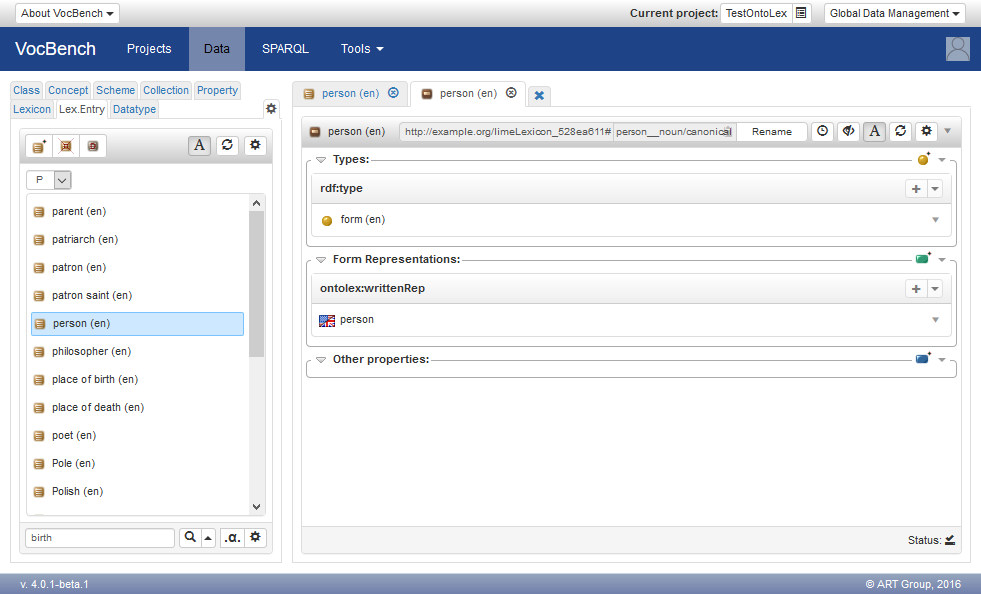
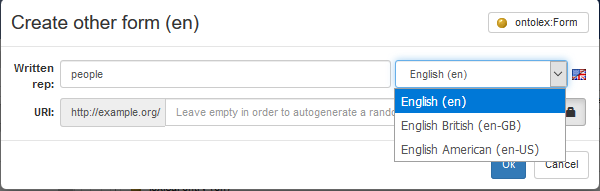
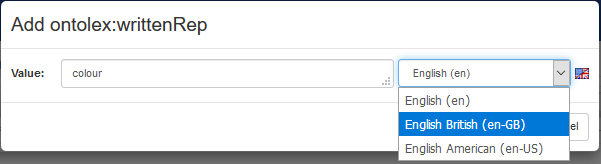
When adding a representation to a form (e.g. a written representation), the system constraints the choice of the natural language based on the one defined in the lexicon. In fact, the system first looks at the lexical entry that is related to the form being edited; however, in the absence of errors, the natural language defined in the lexical entry shall match the one defined in the lexicon. In the following example about an English lexicon, we add the British spelling "colour" to a form as an additional written representation (possibly, accompanying the written representation "color" for the American spelling).
Changes to the Concept and Scheme Sections
In an OntoLex project, the behavior of the Concept and Scheme Sections is changed in the following ways:
- the class used for creating a concept is ontolex:LexicalConcept
- the class used fro creating a concept scheme is ontolex:ConceptSet
These changes make it easier to create concept sets as defined by the OntoLex-Lemon model. Another features introduced with the support for OntoLex-Lemon, though not restricted to OntoLex projects, is the possibility to switch the concept tree from a "hierarchy based" to a "search based" visualization mode. The latter, as we have already discussed, is particularly useful to browse collections of concepts that are both large and rather flat. Again the switch can be operated by clicking on the gear button (![]() ).
).
Lemon VocBench Custom Forms
The OntoLex-Lemon model is a collection of related OWL ontologies that define different modules of the overall specification. It is therefore possible, in principle, to edit and visualizing OntoLex-Lemon lexicons using only the triple-level features of a generic ontology/RDF editor. Nonetheless, the reliance of the model on indirection (e.g. the written representation of a form of a lexical entry) and reification (e.g. a form is a resource) makes its hard to create and, consequently, understand the sometimes complex patterns required to represent seemingly simple information. In the previous sections, we have described the capabilities that have been added to VocBench to help users work with such model. However, these capabilities do not cover all possibilities embodied by the OntoLex-Lemon model; in particular, the system is not equally convenient to edit the ontology-lexicon interface, as specified by the synsem module.
This limitation is mitigated by the use of the Lemon VocBench Custom Forms. They implement a subset of the lemon patterns for the ontology-lexicon interface as custom forms that should be used as custom constructors for the class ontolex:LexicalEntry.
Once the custom forms have been bound to the ontolex:LexicalEntry class, upon the creation of a new lexical entry, the user is prompted with the list of available forms, each corresponding to a different design pattern.
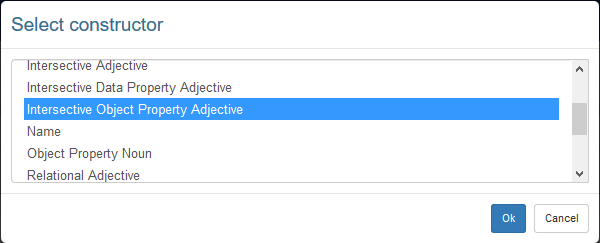
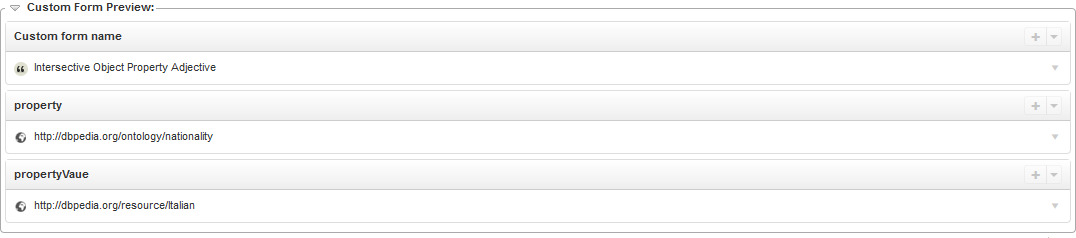
When the user chooses a form (e.g. Intersective Object Property Adjective, that is to say an adjective denoting a class defined as a value restriction on an object property), the form for the creation of the lexical entry is extended with additional fields that are specific to the chosen form (e.g. an object property and its value).
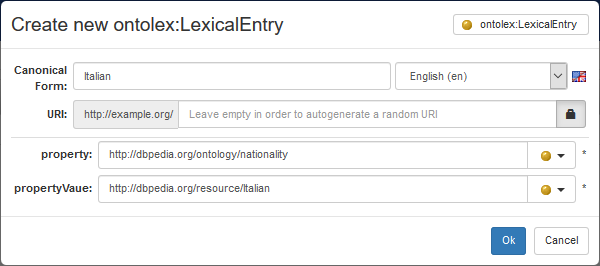
The corresponding lexical entry is a very complex one:
- it has a sense the reference of which is an owl:Restriction (e.g. dbo:nationality value dbr:Italian), with a semantic argument corresponding to the argument of the class (seen as a unary predicate)
- it has two syntactic behaviors:
- one for the predicative usage (e.g. X is Italian), in which we have a copulative subject (e.g. X)
- one for the attributive usage (e.g. Italian X), in which we have an attributive argument (e.g. X)
- each of the aforementioned syntactic argument is bound to the sole semantic argument by means of unification (i.e. use of the same identifier)
It should be quite obvious that the representation of the information above without the use of custom forms would have been quite difficult. Moreover, it is similarly difficult to understand that complex graph pattern, and recognize it as an instance of a lemon design pattern. The custom forms also help visualize and understand complex lexical entries, since the custom forms are applied in "reversed mode": they are matched against the data, and the custom form that best fit the data is used to decode the triples at hand and present a clear form-based preview (including the name of the design pattern and its salient information).