



Dataset Catalogs
Dataset catalogs are remotely accessible directories of ontologies, thesauri, ..., datasets. Actually, catalogs greatly differ in the type of the managed datasets, the range of metadata made accessible and the offered functionalities.
VocBench does not commit to any specific catalog, and relies on the extension point DatasetCatalogConnector to support diverse catalogs. Predefined extensions support the following catalogs:
- Linked Open Vocabularies (LOV): this is a catalog of vocabularies (OWL ontologies and RDFS schemas), which is curated by human editors to assure the quality of its content and accompanying metadata. Individual entries in LOV are associated with an URL to download a cached copy of the vocabulary, but no SPARQL endpoint is provided (since vocabularies are generally intended for the description of the content of other datasets and are thus made available as files).
- The Linked Open Data Cloud: this is the home of the repository behind the famous diagram depicting the datasets being published and interconnected using the Linked Data best practices and made available as open data. Actually, the documentation of the catalog does not prescribe anything on the license, beyond stating that "Access of the entire dataset must be possible via RDF crawling, via an RDF dump, or via a SPARQL endpoint." (more about technical openness than legal concerns about reusability).
- data.europa.eu: The official portal for European data, providing access to a collection of open dataset metadata harvested from international, EU, national, regional, local and geo data portals. It replaces the EU Open Data Portal and the European Data Portal.
- ShowVoc: an open-source software for creating data portals. Initially developed in the context of the ISA2 action Public Multilingual Knowledge Management Infrastructure for the Digital Single Market (PMKI), ShowVoc can be used to set up data portals for specific institutions, companies, etc. ShowVoc is based on the RDF service platform Semantic Turkey, which also supports VocBench. ShowVoc stores a copy of stable contributions in projects alike the ones used in VocBench. Moreover, ShowVoc adopts a dedicated policy to grant anyone access to public datasets, whereas in VocBench users must be assigned to projects. Furthermore, faceted search is based on project facets, both standard ones (e.g. model and lexicalization model) and custom ones (decided for each ShowVoc installation).
- OntoPortal: an open-source software for creating data portals based on the code originally written for the BioPortal ontology repository. In addition to the latter, which has become a reference with respect to biomedical ontologies, other installations cover different domains, such agriculture and environment, which are addressed by AgroPortal and EcoPortal, respectively. VocBench provides a general configuration targeting any OntoPortal installation, together with one specific for EcoPortal.
The figure below depicts the main dialog for the interaction with a dataset catalog. Its main function is to support the user to search a dataset matching some criteria. Currently, this functionality is exploited when "adding an import" or when "preloading a newly created project with some data".
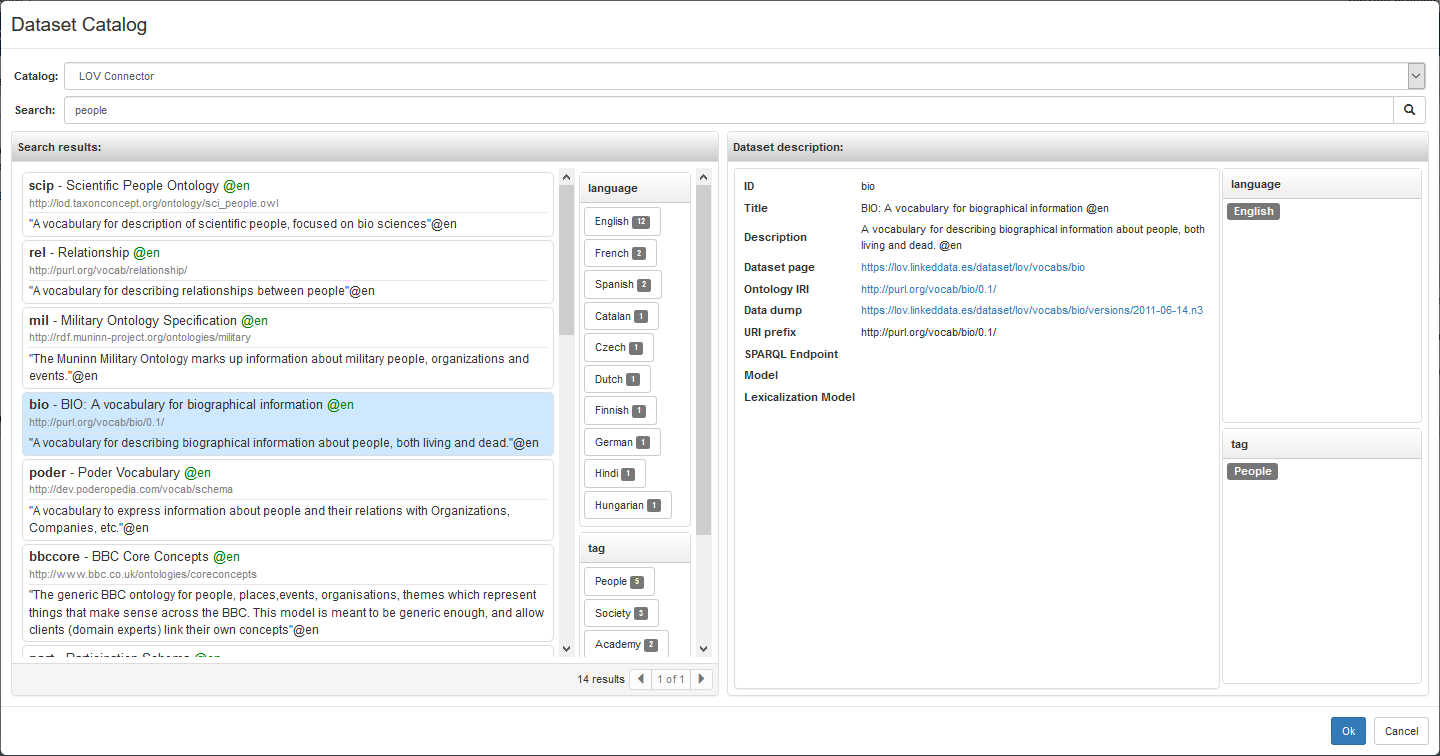
The topmost drop-down list, labeled "Catalog", supports the selection of the catalog to use. The text field just below, labeled "Search", can be used to
enter a search string. To start a search, it is sufficient to hit ENTER (when the cursor is in the search text field) or to press the nearby
button with the magnifier icon.
The search results are listed below the input widgets, sorted by relevance (if returned by the catalog), with the most relevant result at the top. Results are paginated to prevent problems with very large result sets. However, it is indicated the total number of results, the total number of pages and which page is currently shown. The user can move to the previous or to the subsequent page (if they exist) by clicking on the two triangles near the page indicator, respectively, the leftward point triangle and the rightward point one.
If returned by the chosen catalog, search facets are shown on the right of the results list as a sequence of boxes.
The heading of the box contains the name of the facet (e.g. language), while the contained items
indicate different values for the specific facet (e.g. English, French, etc.). The number associated with
each item indicates how many search results have that value for the facet. Users can refine their search by selecting
one or more facets. To that end, it is sufficient to click on the item of interest. Active facets are rendered with a darker color,
and they can be deactivated by clicking on them again.
For each search result, the following information is shown:
- identifier (e.g. bio)
- title (e.g. BIO: A vocabulary for biological information)
- ontology IRI (e.g. http://purl.org/vocab/bio/0.1/). Only available when the dataset can be imported as a single document through this ontology IRI
- description (e.g. A vocabulary for describing biographical information about people, both living and dead)
If a search result is associated with titles and descriptions in different natural languages, the display language is determined as follows in decreasing order of preference:
- user's preferred languages in decreasing order of preference
- English
- any
When the user clicks on a search result, its detailed description is shown on the right side of the dialog. Currently, the description includes a few additional metadata, most importantly the data dump, the SPARQL endpoint and the URI prefix. On the right of the dataset description, there are some boxes, corresponding to catalog-specific facets (e.g. language and tag) used to classify the dataset.
Catalogs may support different access methods (e.g. SPARQL endpoint or data dump), and the datasets in the same catalogs may support different methods.
In general, the presence of specific metadata determines what can be done with a given dataset:
- preloading requires a data dump
- adding an import requires the ontology IRI, optionally benefiting from the data dump