



Global Data Management
The Global Data Management menu provides functionalities for overall management of the data in the project.
Load Data
Please notice that this functionality is meant for loading the data that has to be maintained within the project (e.g. load the latest distribution of the Eurovoc dataset in order to edit Eurovoc within VocBench). If the intent is to owl:import an ontology, in order to create a knowledge base based on it, or to create another ontology extending its model, then the Import functionality in the "Metadata Management" section should be used.
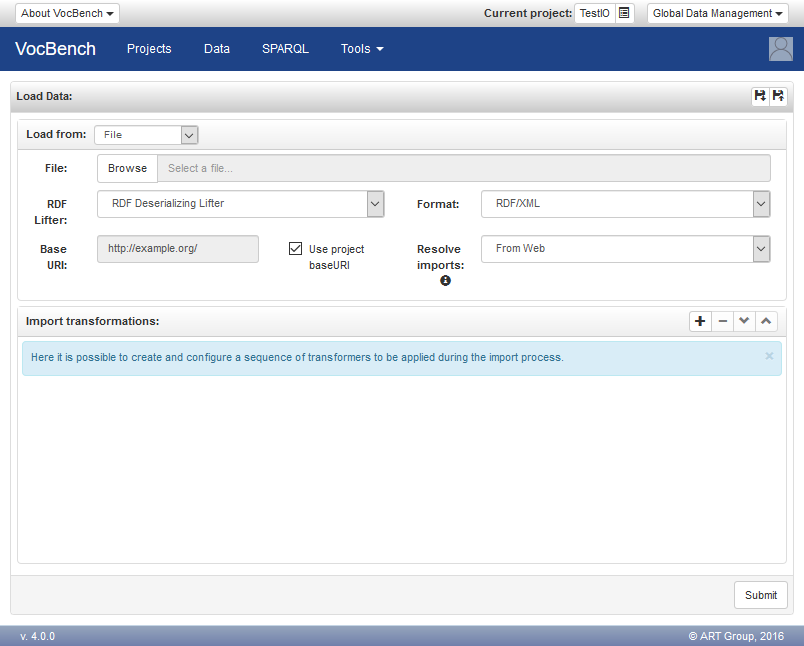
VocBench can load data from a variety of sources such as files, triple stores and custom sources. The desired type of source can be chosen using the combobox labeled "Load from". Depending on this choice, the user shall then configure:
- a loader, which extracts the data from a source
- a lifter, which transforms a byte sequence to RDF. This component is not required when loading data from a triple store, because the loader itself produces RDF data.
The baseuri field is usually not mandatory as the baseuri is generally provided by the data being loaded. The value for the baseuri is used only when the loaded content includes local references (e.g. #Person) and no baseuri has been specified. Formats such as NTRIPLES, which always contain fully specified URIs, never need this optional parameter, and in cases local references are possible (such as in RDFXML), usually the baseuri is provided inside the file.
The data that has been loaded and (if necessary) lifted to RDF can be further processed before it is written in the working graph of the current project. The transformation of the data can be controlled by specifying a sequence of RDF Transformers (more details provided later in the Export Data section). Transformers can operate destructively on a copy of the data being loaded, which are first loaded in a temporary, in-memory repository. Otherwise, this temporary copy is avoided, and the data is directly fed to the project repository.
The "Resolve transitive imports from :" combo box, shows the following possible values, instructing VocBench on how to import vocabularies specified on transitive dependencies, that is, vocabularies that are owl:imported by the loaded data, or by other vocabularies in turn imported by it.
- Web: transitive imports are resolved by trying to import the related vocabularies through their URIs specified in the owl:imports declarations
- Web with fallback to Ontology Mirror: if a vocabulary required by a transitive import is not found on the Web, then the Ontology Mirror will be used as a fallback solution
- Ontology Mirror: transitive vocabulary dependencies will be resolved locally on the Ontology Mirror
- Ontology Mirror with fallback to Web: if a vocabulary required by a transitive import is not found on the Ontology Mirror, then the Web will be used as a fallback solution
Note that the content will be loaded inside the project's working graph, so it is possible to modify it. This is the main difference with respect to the import options on the Import Panel that allow users to import existing ontologies as read-only data. Conversely, the Load RDF option is typically used to reimport data which has been previously backed up from an old repository, or for data exchange among different users.
The flexibility of the "load data" mechanism clearly allows for complex procedures to be defined. To ease the (consistent) reuse of these procedures, VocBench supports saving (and then loading them) on different scopes (system, project, user, project-user), depending on the desired level of sharing. To that end, it is sufficient to use the "floppy disc" buttons inside the header of the window.

It is worth to notice that the configuration of individual components (i.e. loaders, lifters, RDF transformers) are not included inside the configuration of the overall process, but they are only included by reference. In case one these sub-configurations was not saved independently, a dialog like the one below is shown:
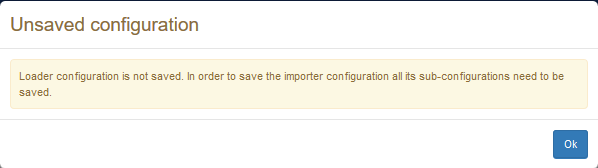
To save and load the configuration of individual components, it is possible to use analogous save/load buttons associated with each configurable component.
Loading Large Amounts of Data on Projects Requiring Validation
When dealing with big datasets in projects with validation enabled, loading the initial data might result in a very slow process, this is because each single triple present in the repository is copied first in the support repository (in its reified form) and in the validation graph of the core repository, and then it needs to be validated, causing another heavy operation for being finalized.
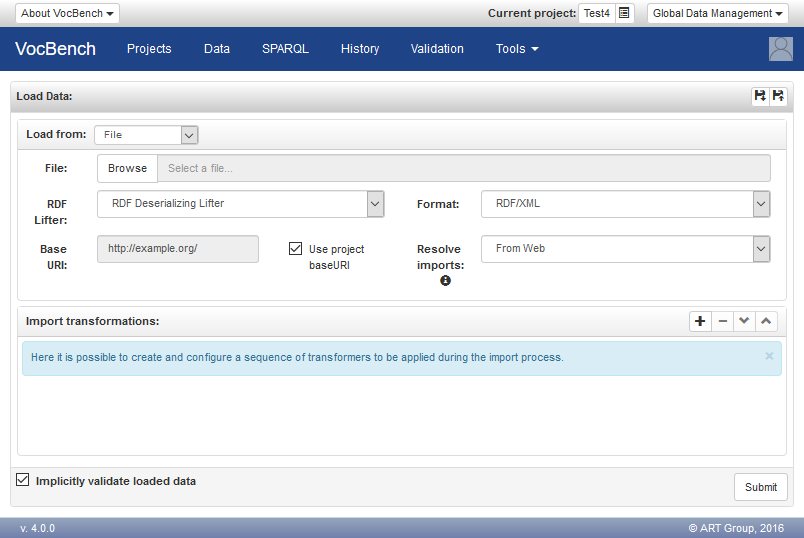
As a solution, authorized users can tick the "Implicitly validate loaded data" option (which appears only in projects requiring validation, and only for authorized users) which, as the options says, skips the validation process and copies the data directly in the repository (if history is enabled though, a copy in the history will be made in any case, still requiring less time than a copy in the validation, and not requesting validators to perform the heavy validation operation later).
Export Data
After selecting the Export Data option, a window like the one in figure below will be shown. The window is organized into three sections, which correspond with the selection of the graphs to export, an optional pipeline of export transformations and a deployment specification. Additionally, a checkbox near the button "Export" can be used to include the inferred statements in the export.
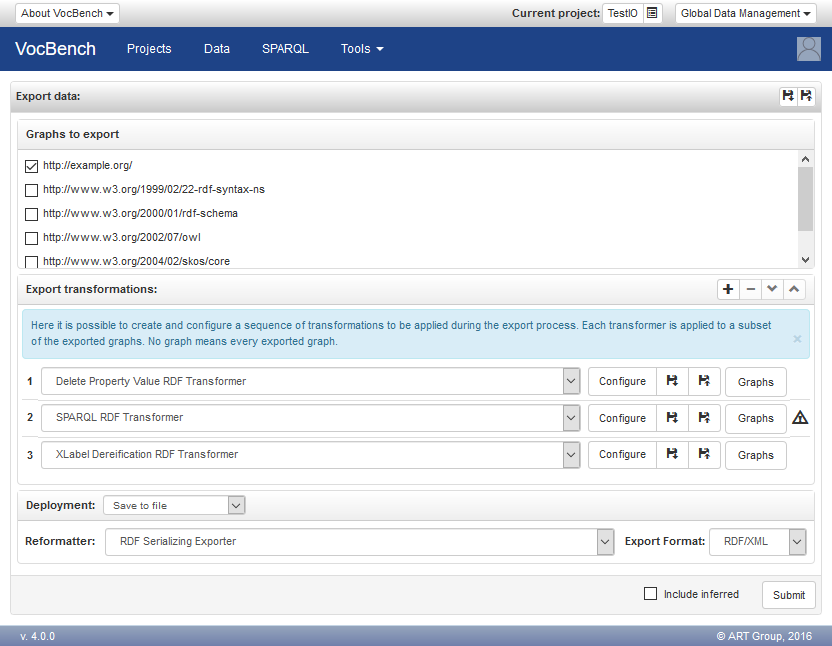
The section, "Graphs to export" lists all the named graphs available in the dataset of the project, so that the user can decide whether to export the sole working data or other information. Note that the provenance information of the graph is maintained depending on the configured deployment specification: serializing the data in a file conforming to quad-oriented formats (e.g. N-Quads, TriX, etc..) allows to keep track of the context each statement belong to, while triple-formats (N-Triple, TriG..) will have all the data merged in the same triple set.
The middle part of the export page concerns the possibility to use RDF transformers for altering the content to be exported according to user preferences. Export transformers range from very specific transformations (e.g. transform all SKOS-XL reified labels into plain SKOS core ones) through user-customizable ones (e.g. DeletePropertyValue, allowing the user to specify a property and a value that should be removed from all resources in the dataset, adopted usually in order to remove some editorial data that is not desired to appear on the published dataset, but repurposable for any need) to completely specifiable transformers, such as the SPARQL Update Export Transformer, that allows the user to completely change the content according to user-defined SPARQL updates. The warning sign near the SPARQL RDF Transformer in the figure above indicates that the user has not already provided the required configuration.
Note that when transformers are adopted, all the content to be exported is copied to a temporary in-memory repository, which can thus be altered destructively by the transformers without corrupting the original data. The export process is optimized in case no transformer has been selected: in this case, no temporary repository is generated and the data is directly dumped from the original dataset.
We have provided a dedicated page for describing useful (and thus reusable) configurations of the RDF Transformers.
The last section, "Deployment", allows to configure the destination of the exported data. Available options are:
- Save to file
- Deploy to a triple store
- Use custom deployer
The first option, "save to file", serializes the exported data as a sequence of bytes that are returned to the browser so that they can be downloaded in a file within the filesystem of the user. The serialization is controlled by the selection of a reformatter, which may optionally require a configuration. Moreover, a combobox labeled "Export Format" allows to select the specific serialization format among the ones supported by the chosen reformatter. In the figure above, it has been chosen to format the data according to the RDF/XML syntax.
The second option, "Deploy to a triple store", uses a deployer supporting destinations that (broadly speaking) are a triple store. The figure below shows the use of the deployer implementing the SPARQL 1.1 Graph Store HTTP Protocol to save the data to a graph of a compliant (remote) triple store.

The third option, "Use custom deployer", uses deployers for byte oriented destinations: consequently, the user shall also select a reformatter, which translates the RDF data to the actual sequence of bytes that will be deployed. The figure below shows the possibility to deploy the data to an SFTP server after that they have been converted to the Zthes format.

The mechanisms that have been described so far allows for the definition of very complex export procedures. The "floppy disc" buttons inside the header of the window allow to save and load the configuration of a complete export procedures. Configurations are identified by a name, and they can be saved to different scopes (system wide, project, user, project-user), to support different sharing options (e.g. a configuration may be made available to every user of a project, or saved privately by a user).

The saved export configuration does not include the configurations of the components it uses (i.e. RDF transformers, reformatters and deployers), rather it includes references to these configurations, which shall be saved independently. The figure below shows an error occurred while saving an export configuration that depends on an unsaved configuration of a deployer.
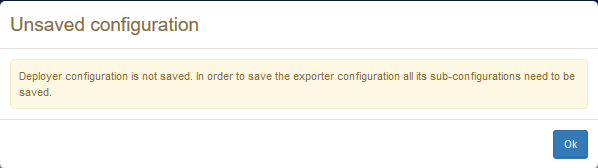
To save and load the configuration of individual components, it is possible to use analogous save/load buttons associated with each configurable component.
Clear Data
Through this action, the project repository will be completely cleared.
Needless to say, pay attention to this action because it erases all information in the project (we recommend to save the existing data before clearing it).
Change working graph
The repository associated with a project may contain multiple named graphs. These include the main graph named after the project base URI and containing the data being edited, and zero or more graphs each named after a (transitively) imported ontology and containing its data. When validation is active, variants of these graphs can be created to account for triples being added or deleted.
As anticipated, operations modify by default the content of the main graph, while other graphs are considered read-only (imported ontologies) or managed by the system according to its own strategy (graphs supporting validation). However, it doesn't have to be that way and, indeed, the concept of working graph has been introduced to reference the graph being edited. Referencing by default the main graph, the working graph can be reassigned to a different graph by users with the capability rdf(graph), U. Actually, this capability is checked by the backend server each time a write operation is being executed against a graph other than the main graph
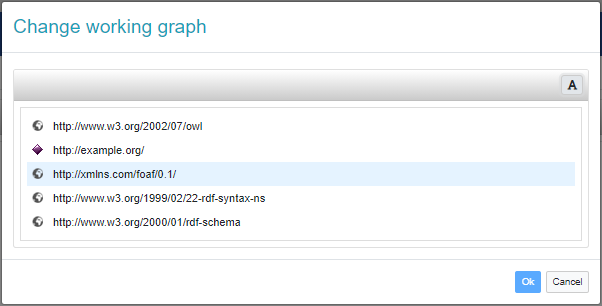
When the working graph doesn't reference the main graph, it is displayed at the top of the page.

Users may also define a custom working graph to temporarily redirect editing operations to a different target graph. In this context, it is also possible to override the base URI, which will be applied not only to the working graph itself but also when creating new resources, ensuring consistent naming within the selected context.


Data Refactor
The Data Refactor page allows the administrator or project manager (or equivalently authorized user) to perform massive refactoring of the loaded data. Note that this refactoring is usually performed at the beginning of the life of a project, usually after some data has been loaded from an external file. This is because the data is non-conformant to the specifications of the project (e.g. the dataset contains SKOS core labels while the project is thought for managing SKOS-XL lexicalizations) and might need to be refactored in order to be properly managed with the intended project settings and configuration.
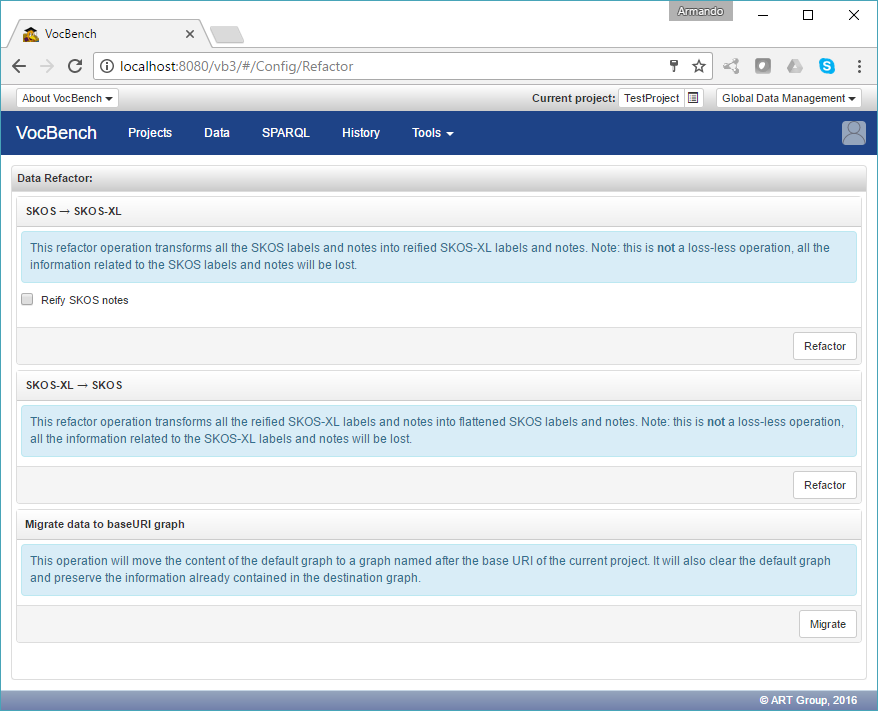
Current refactoring options include going back and forth from SKOS to SKOS-XL and migrating data from the default graph (i.e. the single unnamed graph in the repository) to the working graph (i.e. the graph named after the baseuri of the dataset, which is supposed to hold the working data).
Load Shapes
If SHACL shape validation was enabled, it is possible to load shape definitions from an RDF file conforming to any of the serializations supported by VocBench.
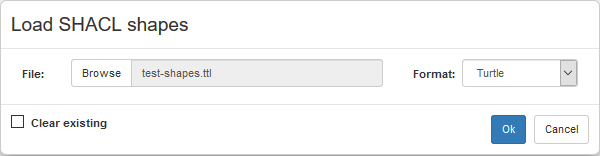
The dialog prompts for a file containing the shape definitions to load, allowing to specify the file format (guessed from the extension of the file). The checkbox "Clear existing" shall be checked, if already existing shape definitions should be deleted. Otherwise, the definitions just loaded are simply added to the existing ones.
SHACL shapes enable the definitions on constraints over the data graph. By default, any edit of the data that would result in a violation of any of these constraints will be rejected by the system. Actually, this setting can be changed upon project creation or afterwards by editing project settings. Shape validation is complementary to reasoning, which uses ontological axioms to draw inferences and check the consistency of the represented knowledge. While the latter may be related to shape validation, the semantics of RDF(S)/OWL makes difficult to reduce checking data integrity to consistency checking. In particular, the open-world and non-unique name prevent the verification of cardinality constraints (e.g. having two values for a functional property is consistent, as long we can't prove that they are semantically different) and existential constraints (e.g. because we shall merely infer the existence of the missing value, which could defined elsewhere). Conversely, SHACL allows to predicate over the actual data under a closed-world perspective and supports elaborate constraints over the data, which in some cases may not be represented by means of RDFS/OWL.
We make a concrete example for the use of SHACL in the context of a test project using SKOS as model and SKOS-XL as lexicalization model.
When adding a skos:note to a concept, VocBench asks whether the note should be a resource, typed literal or plain literal. These possibilities stem from the fact that skos:note is ontologically defined as an owl:AnnotationProperty, without effectively constraint the kind of objects for that property. From the ontological viewpoint any choice would be consistent. Choosing a different annotation style for different concepts would be consistent as well. However, the latter is probably forbidden by guidelines that may prefer uniform data modelling.
The following SHACL shape can be used to enforce that any skos:note of a skos:Concepts shall be a IRI, which in turn is associated with the actual note (represented as a language tagged string) through the property rdf:value. This pattern is known as reified notes.
@prefix ex: <http://example.org/> .
@prefix owl: <http://www.w3.org/2002/07/owl#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix sh: <http://www.w3.org/ns/shacl#> .
@prefix skos: <http://www.w3.org/2004/02/skos/core#> .
ex:ReifiedNoteShape
a sh:NodeShape ;
sh:targetClass skos:Concept ;
sh:property [
sh:path skos:note ;
sh:nodeKind sh:IRI ;
sh:property [
sh:path rdf:value ;
sh:minCount 1;
sh:nodeKind sh:Literal ;
sh:datatype rdf:langString
]
]
.
After loading the shape above, any attempt to add a language-tagged literal as a skos:note should fail with a message like the one below:

The error dialog reports on the constraints violated by the proposed change:
- the one focused on the subject resource (e.g. <http://test.it/c_1cf1b652>) tells that the value of skos:note is not a IRI
- the one focused on the actual definition provided as text, obviously, tells that the definition (which can not be described further in RDF) does not have the property rdf:value
Loading suitable SHACL shapes allowed for constraining how skos:notes can be represented. The problem, however, is how to enable the addition of conforming notes as in a single operation that would pass the shape validation. The solution to this problem is to use custom forms, which enable the instantiation of arbitrary graph patterns, when instantiating a class (i.e. custom constructors) or setting the value of a property (i.e. custom ranges).
Continuing the running example on reified notes, it is not necessary develop a new custom form, since VocBench already ship a suitable one. As described in the documentation, it is sufficient to map the custom form for reified notes to the (suggested) property skos:note (and then check the option to replace the existing range, since it doesn't satisfy the loaded shape).
Subsequent attempts to create a skos:note will open a form like the one below, which prompts for other information (not constrained by the shape) that will be added to the reified note:
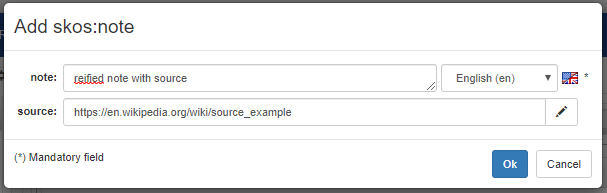
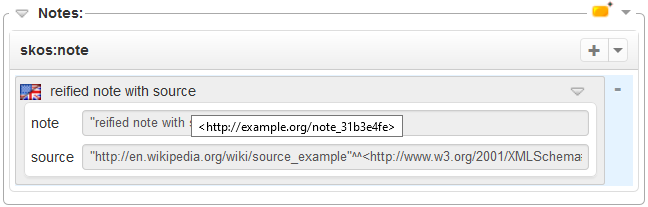
The custom forms is also used in the resource view to show the reified note with its textual content (rather than its IRI that can be seen in the tooltip), while other fields of the custom form are shown in a form-based preview of the note.
Export Shapes
It is possible to download the currently loaded shapes as a nicely formatted Turtle file.
Clear Shapes
Deleting any shape clearly makes the validation ineffective.
Batch Validation
Batch validation refers to the possibility to validate the entire repository against previously loaded shapes and produce a validation report describing any constraint violation. This kind of validation makes sense when (on commit) validation (discussed above) is not enabled or it has been re-enabled after a few (unvalidated) commits; otherwise, interactive SHACL validation would ensure that no violation can be ever found.
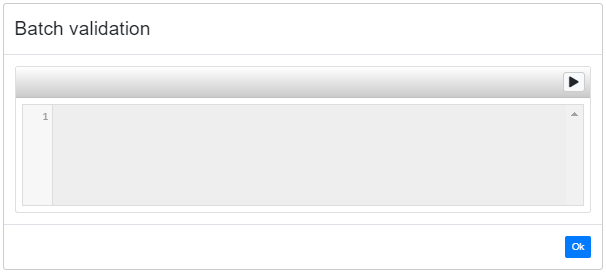
Click on the "play" button in the header to start the actual validation. When it is complete, the validation report will be shown in the (initially empty) text area underneath.

The report (in RDF) is written as pretty-printed and abbreviated Turtle, and it conforms to the SHACL validation report specs. The text area supports syntax coloring and references to (domain) resources (usually occurring as focus nodes) can be clicked to open their resource view: these clickable references stand out well in the report, as they are noticeably highlighted in yellow.