Test Drive: creating projects and loading data
This is a series of simple test drives for you to try VocBench in creating projects and loading data to be managed withing them.
These tests assume that VocBench has already been started for the first time and that the administrator is logged into the system.
Creating a SKOS Project for Managing a Small Thesaurus
In this test drive we create a project for managing a simple SKOS thesaurus, the "Land and Water" FAO vocabulary (which is available for download here), by using the embedded RDF4J store.
Once logged in, the list of projects available in VocBench is shown (obviously empty if VocBench has just been installed)
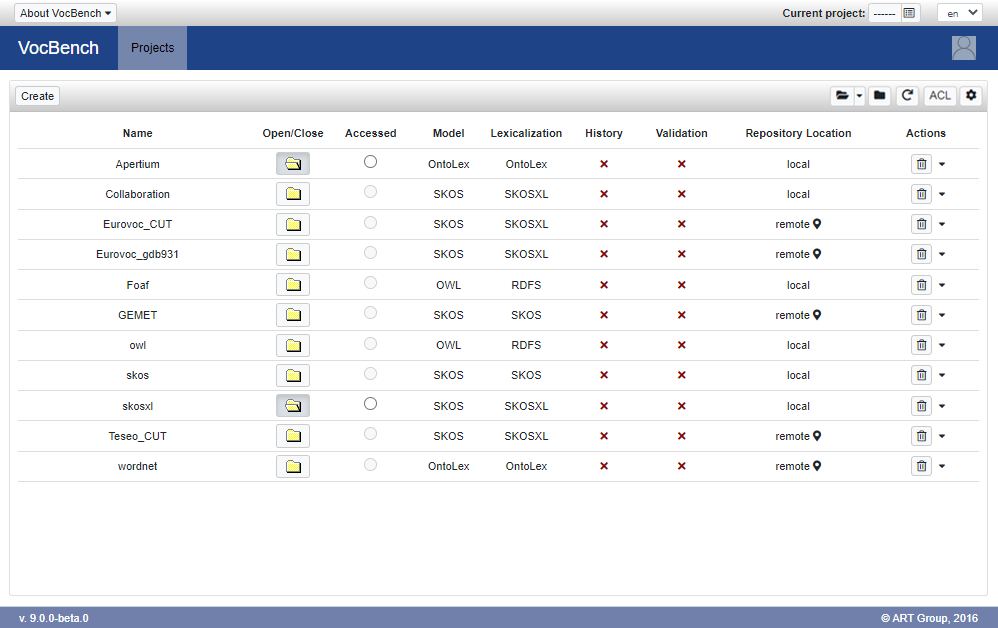
Click on the "Create" button in order to access the following project creation page:
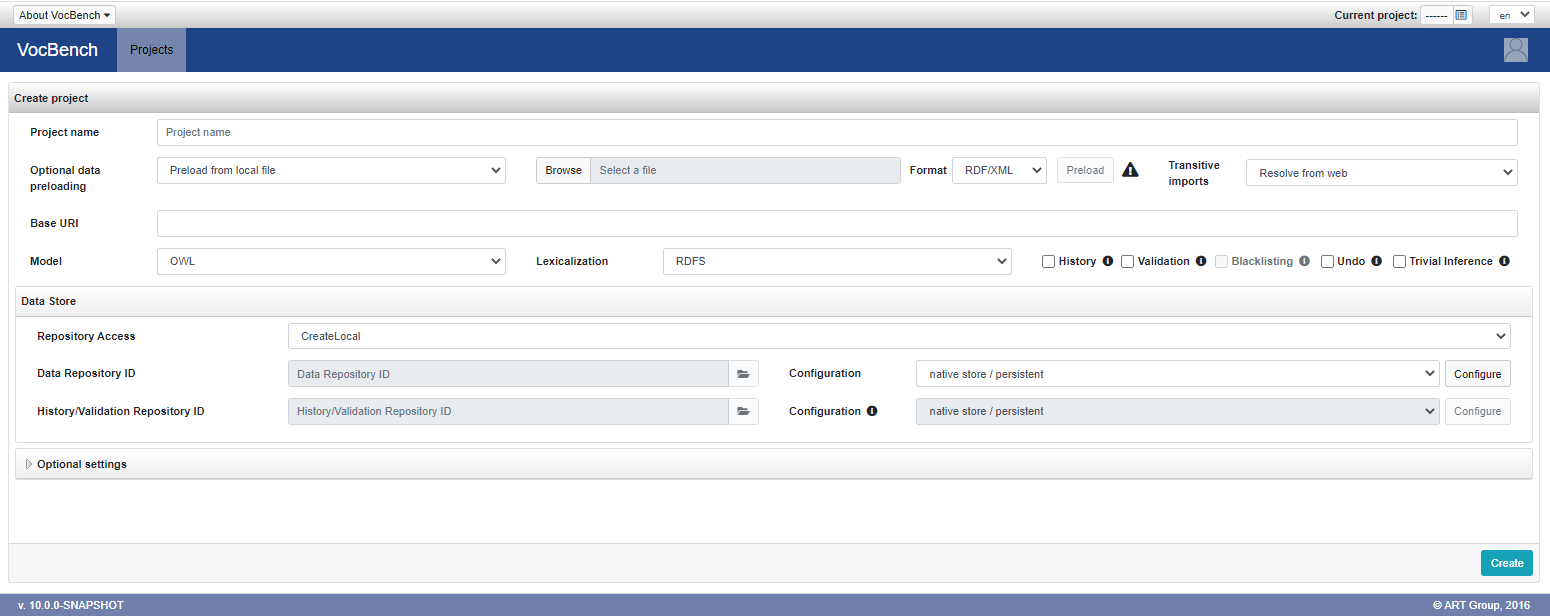
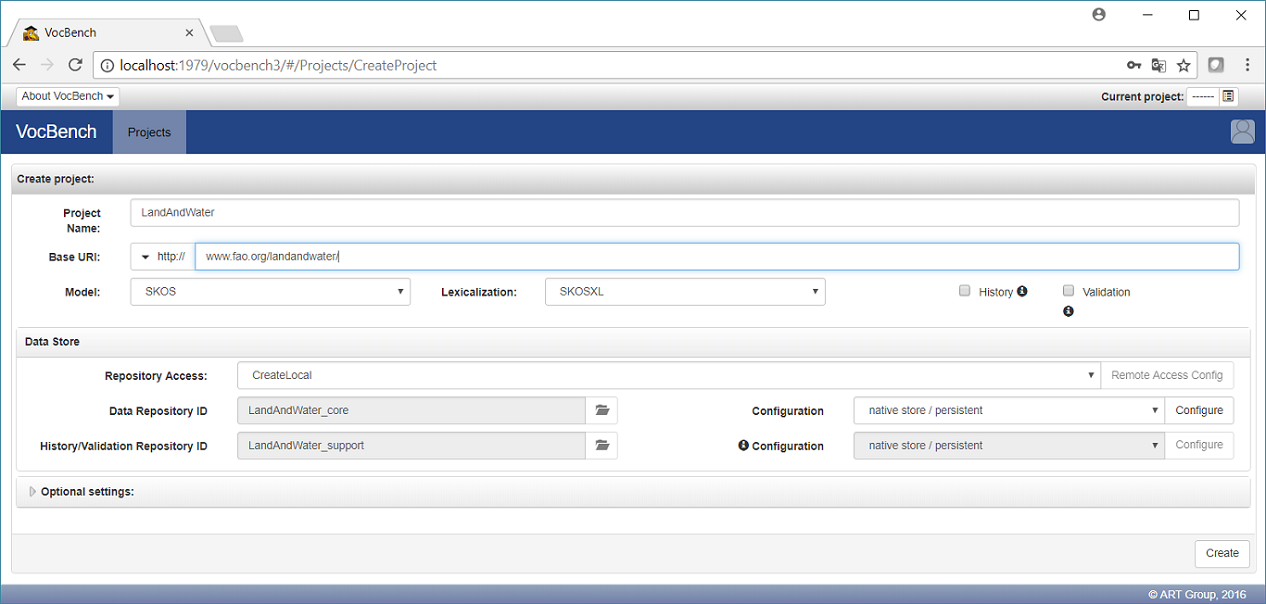
Fill the fields as in the following text and image below:
- Project Name: LandAndWater
- Base URI: http://www.fao.org/landandwater/ (it is important to keep the trailing "/" )
- Type: SKOS
- Lexicalization: SKOSXL (the Land and Water thesaurus we are going to load contains reified labels, expressed with the SKOSXL standard)
- leave everything else as is
a. Loading the thesaurus data
Download the Land and Water thesaurus RDF file
Go to the Global Data Management and select "Load Data", as described here
Just click on the "Browse" button next to the RDF file label and choose the Land And Water data file you have previously downloaded. Leave all the other fields unchanged, as in the following figure.
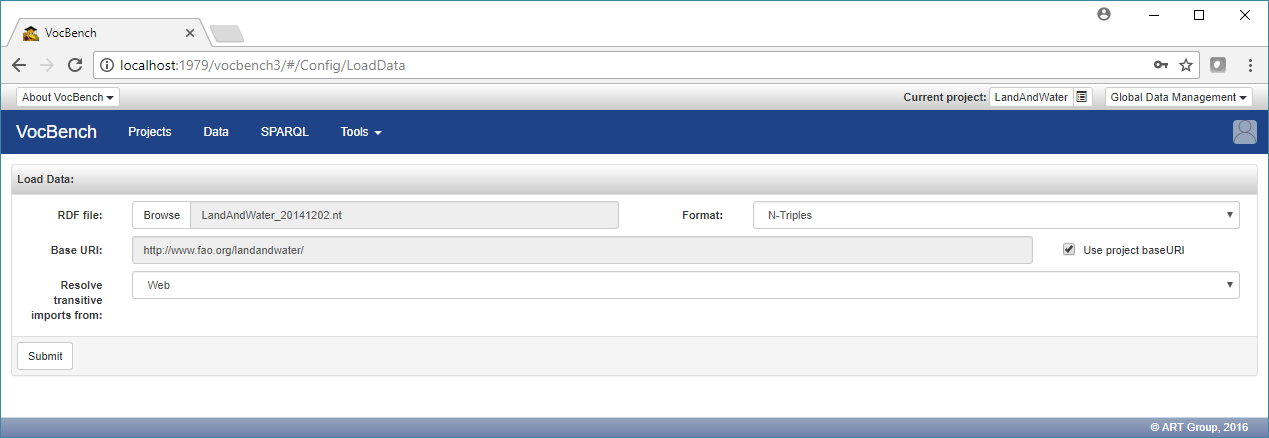
and then click on the "Submit" button. A confirmation message will inform you that the data has been loaded successfully.
By clicking on the "Data" menu entry, it is possible to view the loaded thesaurus.
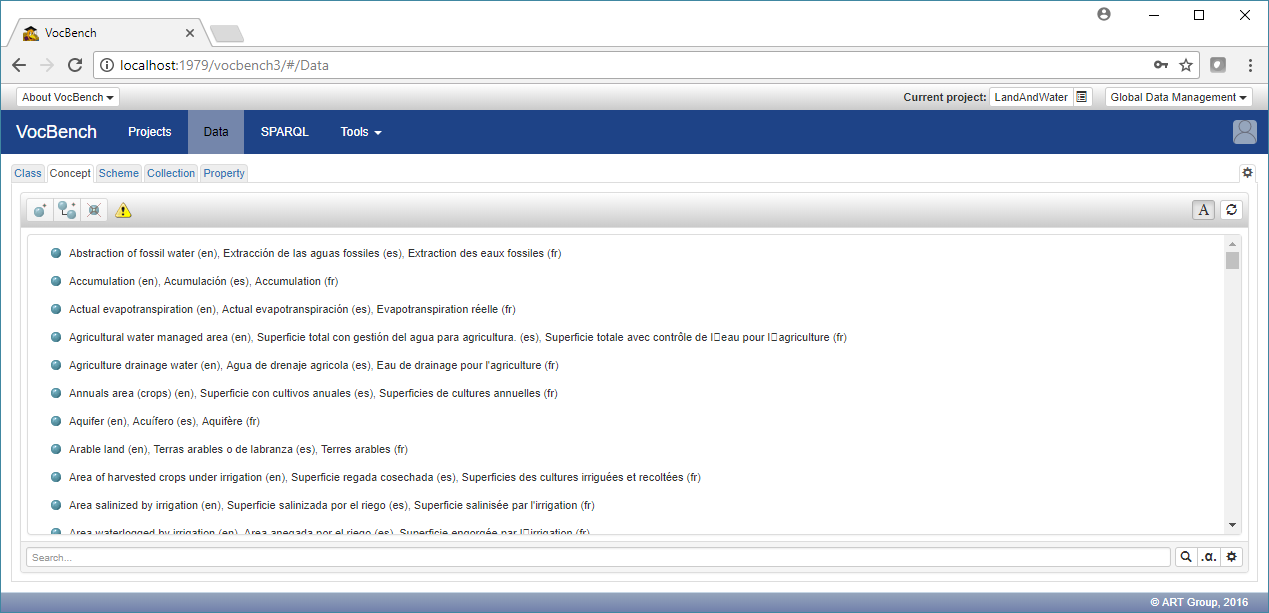
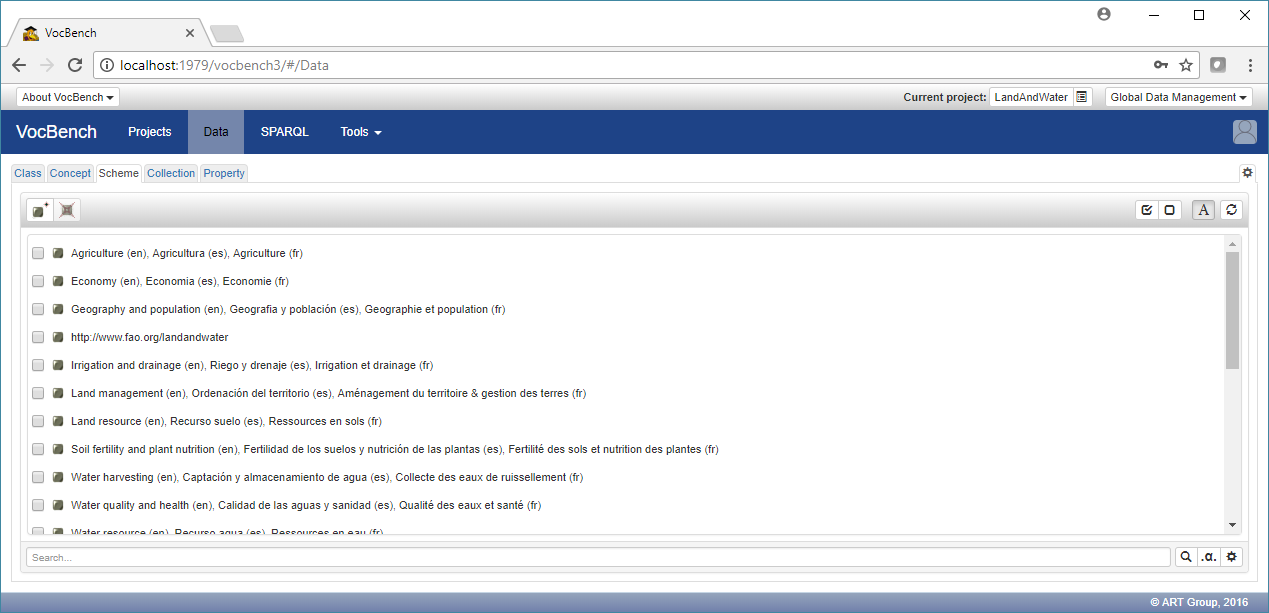
The "warning" yellow symbol informs us that no concept scheme has been selected, thus all concepts in the thesaurus are being shown. By clicking on the "Scheme" tab it is possible to select one (or more) of the available schemes so that the "Concept" tab will now show only those concepts belonging to it (or them).
Creating an OWL Project for Managing an Ontology
In this test drive we create a project for managing an OWL ontology, the "Friend of a Friend" vocabulary (which is available for download here), by using the embedded RDF4J store.
Once logged in, the list of projects available in VocBench is shown (obviously empty if VocBench has just been installed)
Click on the "Create" button in order to access the following project creation page:
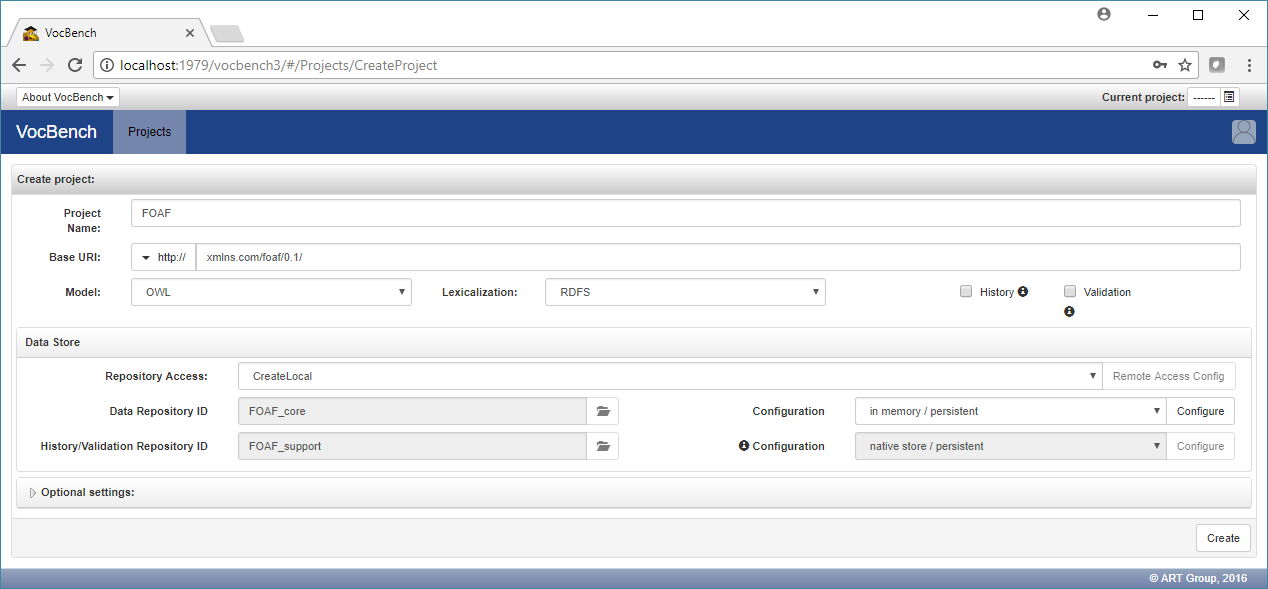
Fill the fields as in the following text and image below:
- Project Name: FOAF
- Base URI: http://xmlns.com/foaf/0.1/ (it is important to keep the trailing "/" )
- Type: OWL
- Lexicalization: RDFS (the Friend of a Friend ontology we are going to load contains only simple rdfs:labels)
- Configuration: in memory / persistent (we will use this configuration as the FOAF ontology is very small and can be easily managed in-memory)
- leave everything else as is
a. Loading the ontology data
Download the FOAF ontology RDF file
Go to the Global Data Management and select "Load Data", as described here
Just click on the "Browse" button next to the RDF file label and choose the FOAF data file you have previously downloaded. Leave all the other fields unchanged, as in the following figure.
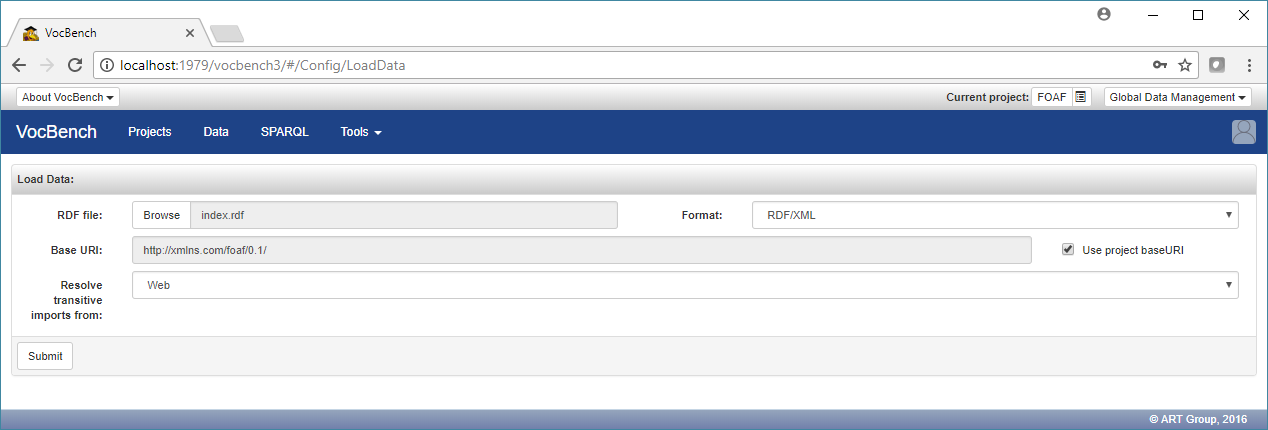
and then click on the "Submit" button. A confirmation message will inform you that the data has been loaded successfully.
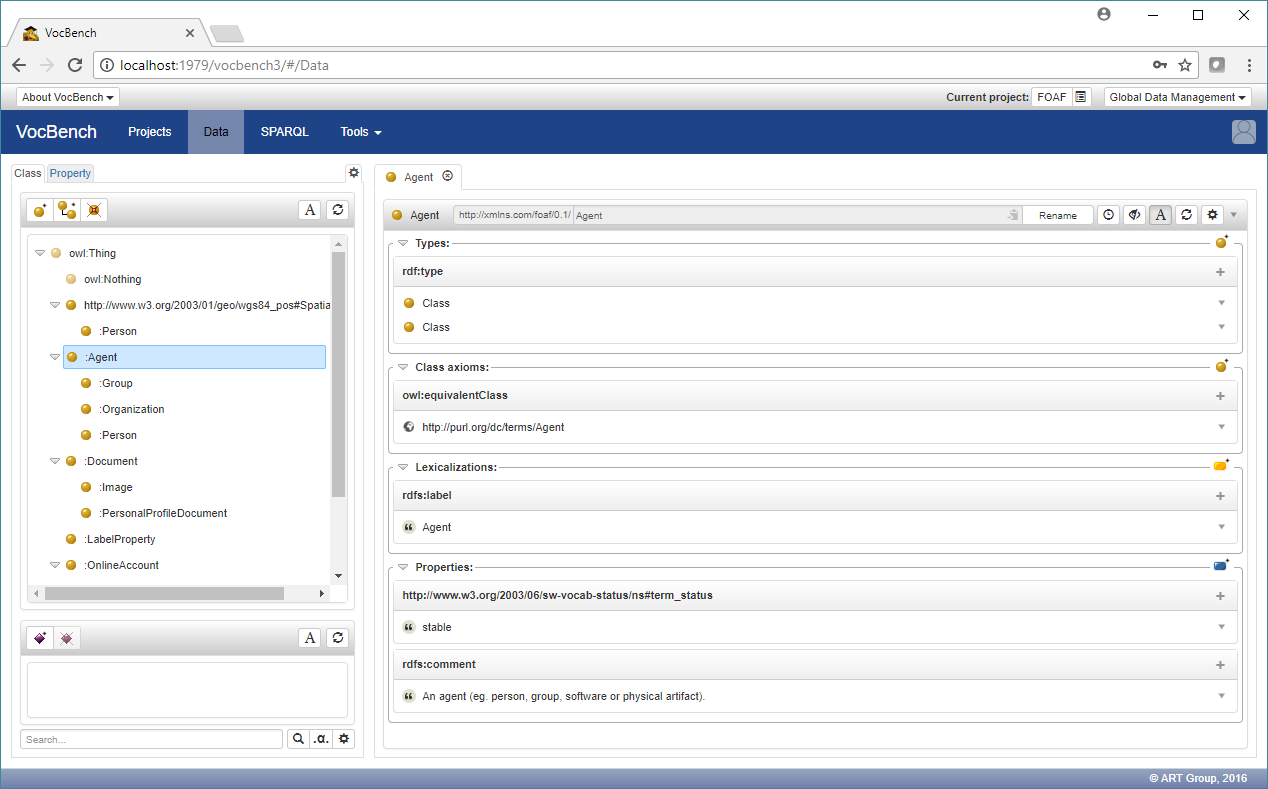
By clicking on the "Data" menu entry, it is possible to view the loaded ontology.
Creating a SKOS Project for Managing a Large Thesaurus by Connecting to an External Triple Store, Exploiting History, Validation and Inference,
In this test drive we create a project for managing a large SKOS thesaurus, the "Eurovoc" thesaurus published by the Publications Office of the European Union. We provide here a dump of Eurovoc which has already been cleaned of duplicate data. The project will enable the History and Validation features and will be relying on an external triple store: GraphDB.
a. Setting up and Running GraphDB
By first, setup the GraphDB server.
If GraphDB has never been used with VocBench, and since we desire to activate the History an Validation features in this test drive, the change-tracking sail component must be deployed into the triple store. Follow the instructions for doing that in the related section of the system administration manual.
Once the change-tracking sail component has been deployed into GDB, it is possible to start the triple store.
b. Creating the Project
Log into VocBench, the list of projects available in VocBench will be shown (obviously empty if VocBench has just been installed)
Click on the "Create" button in order to access the following project creation page:
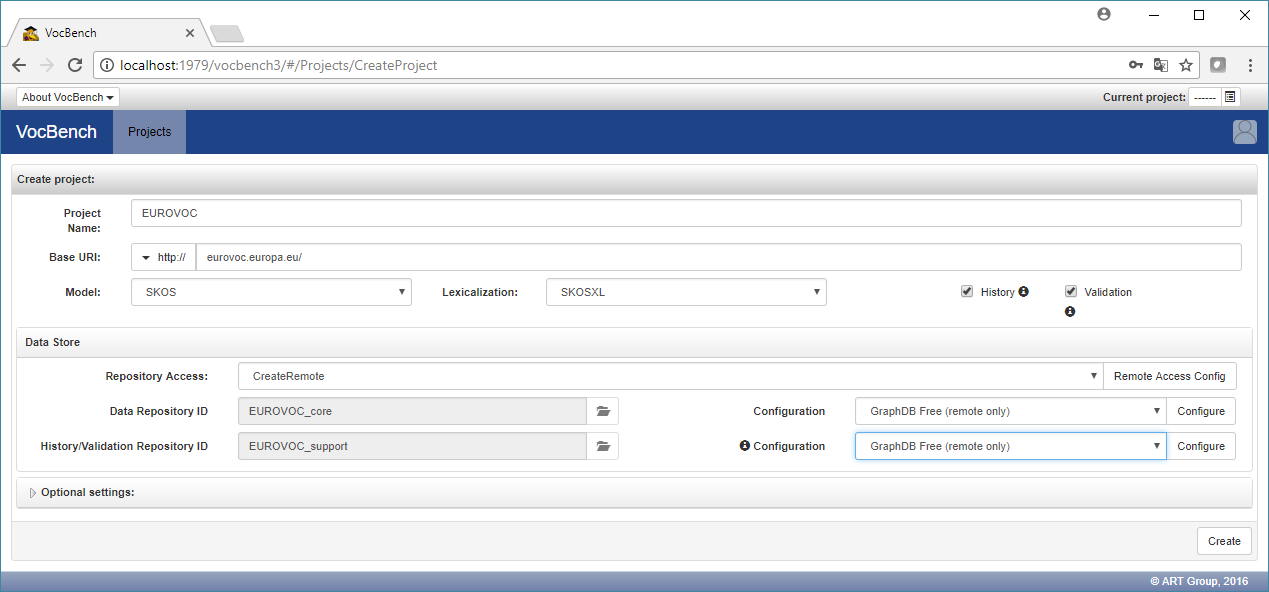
Fill the fields as in the following text and image below:
- Project Name: EUROVOC
- Base URI: http://eurovoc.europa.eu/ (it is important to keep the trailing "/" )
- Type: SKOS
- Lexicalization: SKOSXL (the Eurovoc thesaurus we are going to load contains reified labels, expressed with the SKOSXL standard)
- History and Validation: enable both options
- Repository Access: set to CreateRemote
- Configuration (next to Data Repository ID): set to GraphDB Free (remote only)
- Configuration (next to History/Validation Repository ID): set to GraphDB Free (remote only)
The click on the "Remote Access Config" button, which leads to the following window:
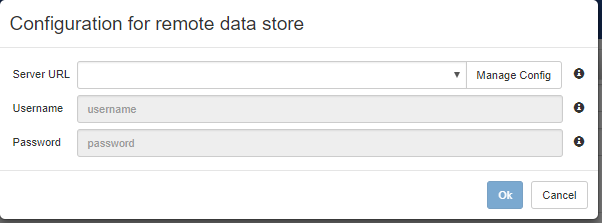
By first create a new configuration, through the "Manage Config" button, which leads to the following window, where you have to insert the address where GDB is listening (we assume here that everything has been installed on the same machine, so that a "localhost" 127.0.0.1 address would work). Unless authorization credentials have been configured in GDB, no username and password is required.
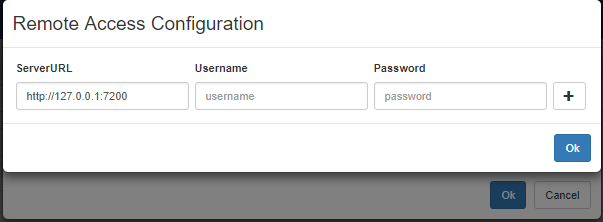
By clicking on the + button the configuration will be saved, as in the following figure
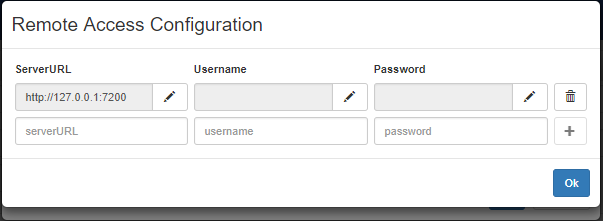
After clicking on the "OK" button in the previous window, it is possible to select through the "Server URL" combobox the configuration previously setup, so that the window will look like this:
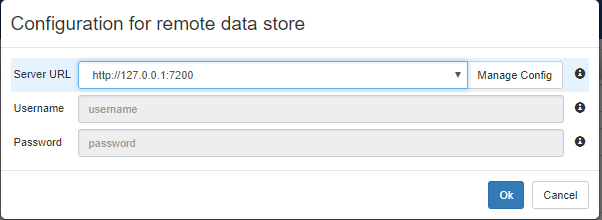
After clicking on "OK" on the previous windows, we come back to the Project Creation page:
We now setup the configuration for the core repository being created for storing the Eurovoc data, by clicking on the first of the two "Configure" Buttons, related to the "Data Repository ID", and changing only one field, the "ruleset" one, setting it to "owl-horst-optimized", and leaving everything else as is.
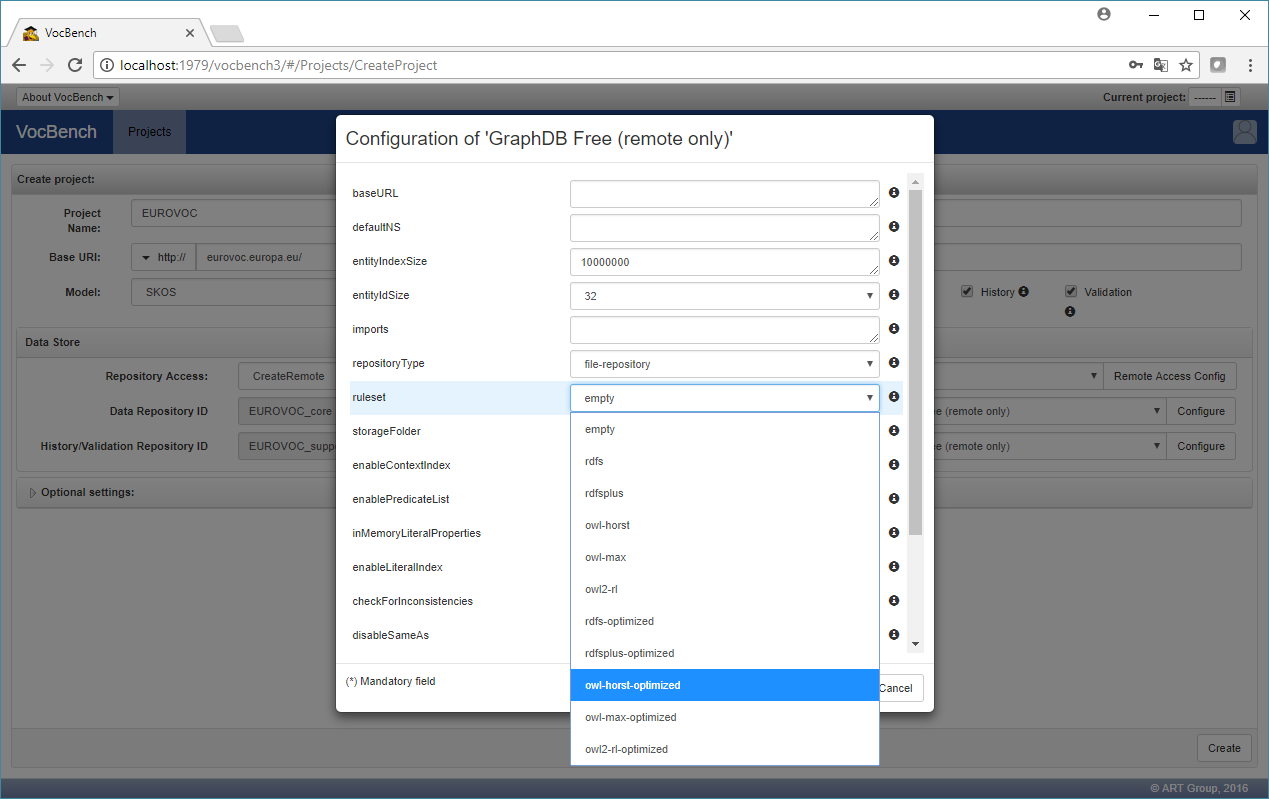
We leave the other configuration unchanged (no need to click at all on the other "Configure" button), and finally click on the "Create" button at the bottom of the page, thus creating the project and the two repositories (core and support for history/validation) on GraphDB.
c. Loading the thesaurus data
Download the Eurovoc thesaurus RDF file and unzip it.
Select the newly created project, then go to the Global Data Management (top-right menu) and select "Load Data", as described here
Click on the "Browse" button next to the RDF file label and choose the Eurovoc data file you have previously downloaded.
It is important that the "Implicitly validate loaded data" checkbox is ticked, otherwise all the loaded Eurovoc data will be subject to validation, consuming lot of unwanted resources.
Leave all the other fields unchanged, as in the following figure:
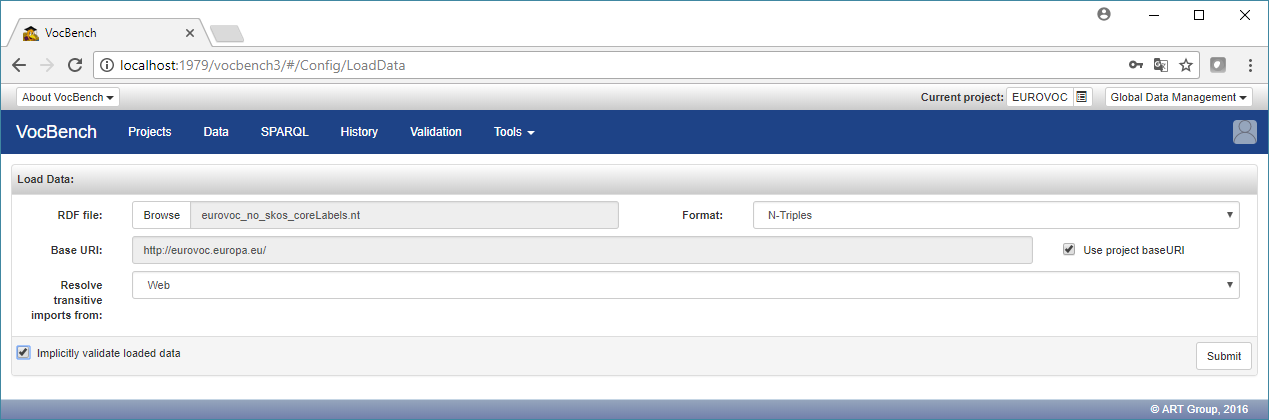
and then click on the "Submit" button.
The data loading process can take quite a few minutes (depending on the underlying hardware) as the hundreds of thousands of triples of Eurovoc are loaded both in the core repository and in the support repository, for purpose of history (validation has been skipped by ticking the option for implicit validation). On a modern Microsoft Surface with an i7 processor, 16Gb of memory and SSD hard disk, it takes less than 6 minutes.
A confirmation message will inform you that the data has been loaded successfully.
By clicking on the "Data" menu entry, it is possible to view the loaded thesaurus.
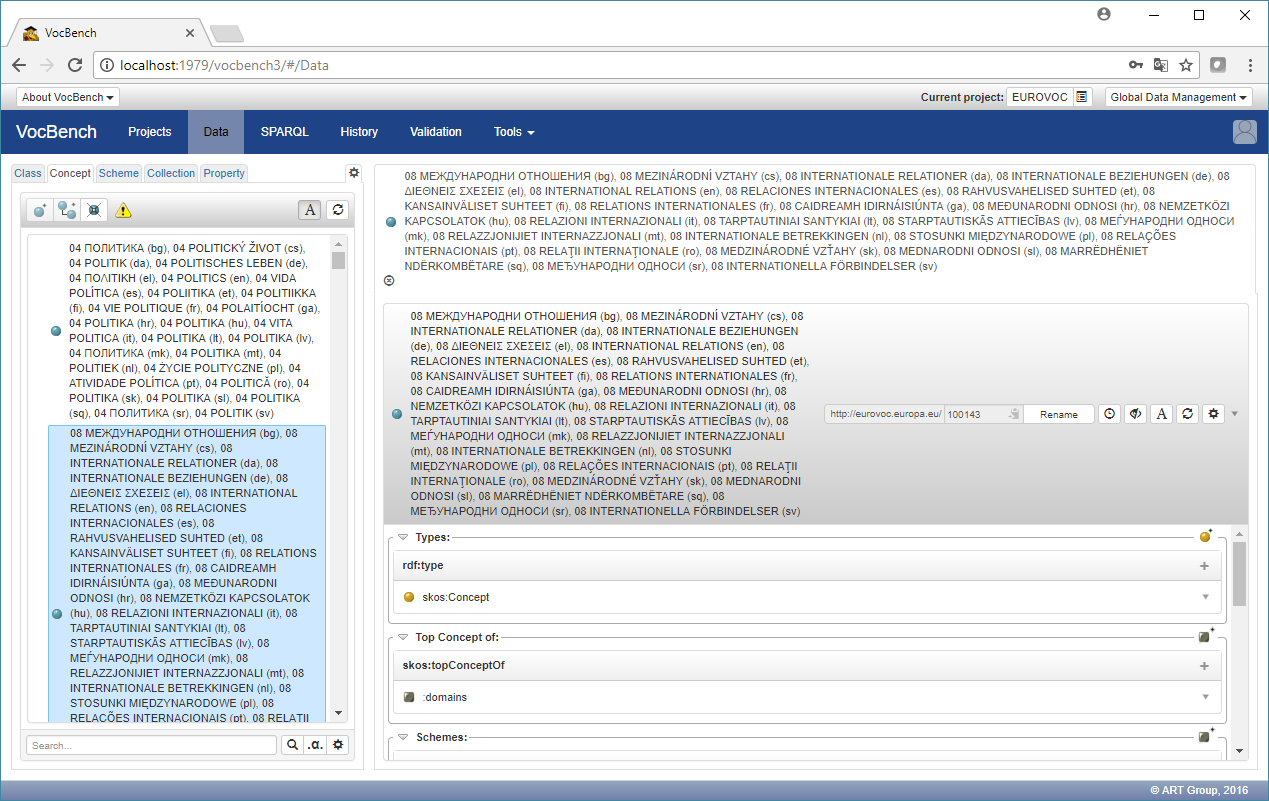
However, there are two inconveniences that limit the usability:
- all labels from all languages of Eurovoc are being used to render the concepts
- no scheme has been selected, so all concepts are being shown (this is not a real issue - even though signaled by the warning triangle icon - for browsing the dataset, as simply all concepts are being shown, but the user might want to select a scheme for browsing Eurovoc by topic)
By clicking on the user icon on the top-right corner of the application, it is possible to select the language that the user is proficient with:
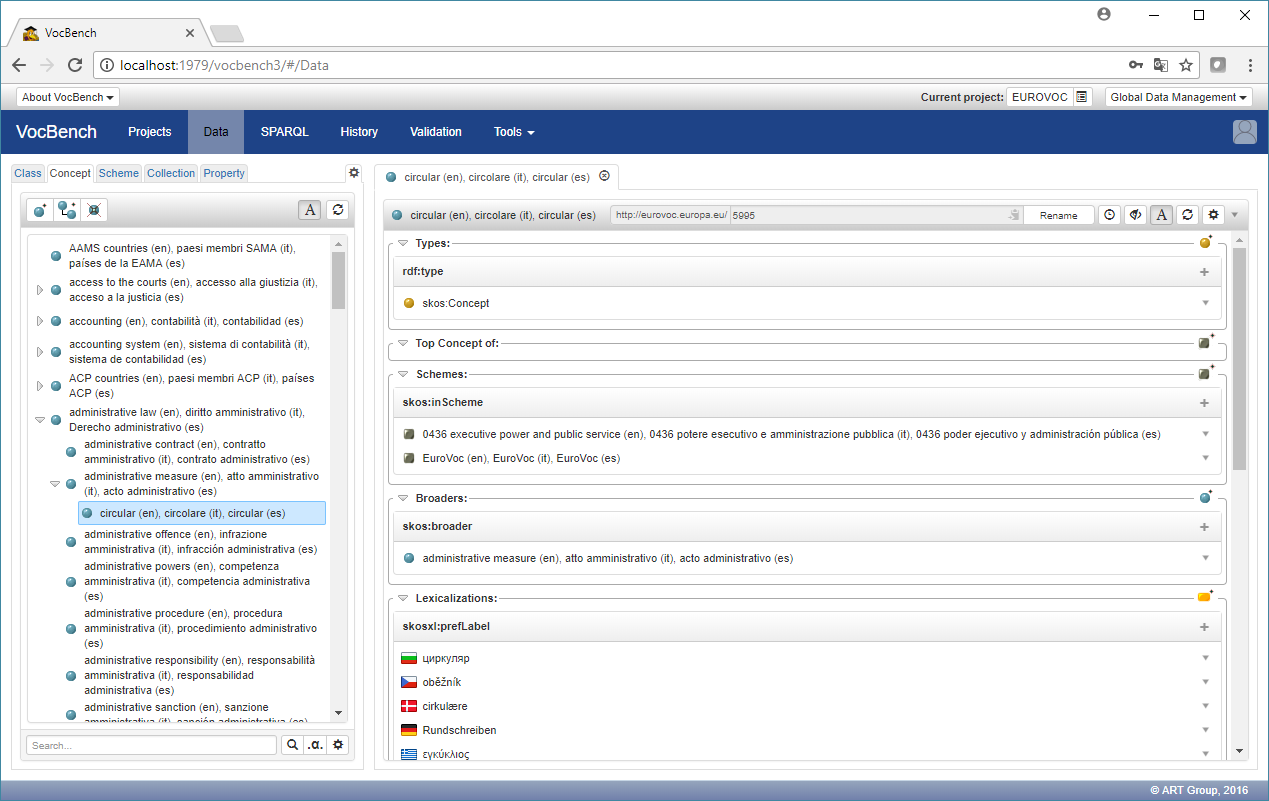
Going back to the data section, by clicking on the "Scheme" tab it is possible to select one (or more) of the available schemes so that the "Concept" tab will now show only those concepts belonging to it (or them).
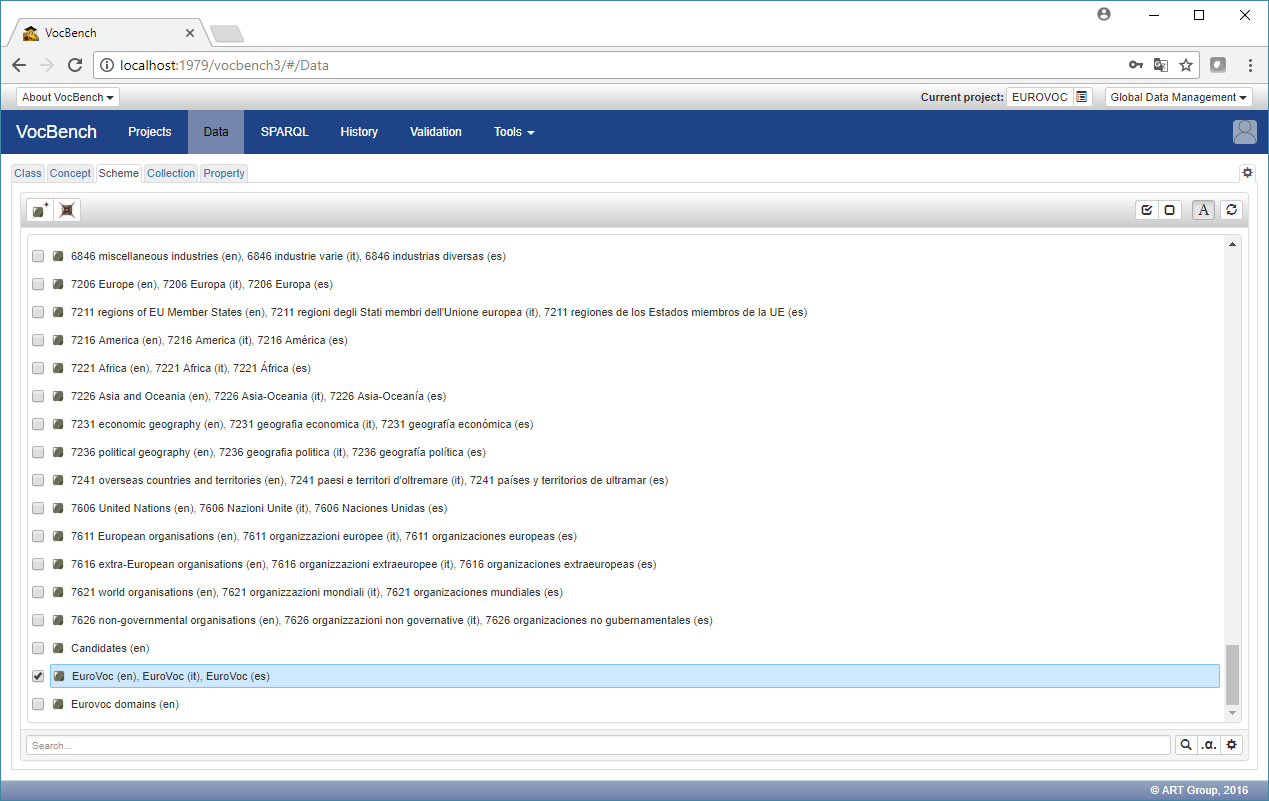
In this case, we have selected the global "EuroVoc" scheme, which contains all concepts in the thesaurus, finally shown in the following figure (a refresh of the concept tree, through the dedicated circular icon, might be necessary)
Creating a OntoLex Project for Managing a Large Lexicon by Connecting to an External Triple Store
In this test drive we create a project for managing a large Lexicon , the "Wordnet" Lexicon. The project will be relying on an external triple store: GraphDB.
a. Setting up and Running GraphDB
By first, setup the GraphDB server.
If GraphDB has never been used with VocBench follow the instructions for doing that in the related section of the system administration manual.
b. Creating the Project
Log into VocBench, the list of projects available in VocBench will be shown (obviously empty if VocBench has just been installed)
Click on the "Create" button in order to access the following project creation page:
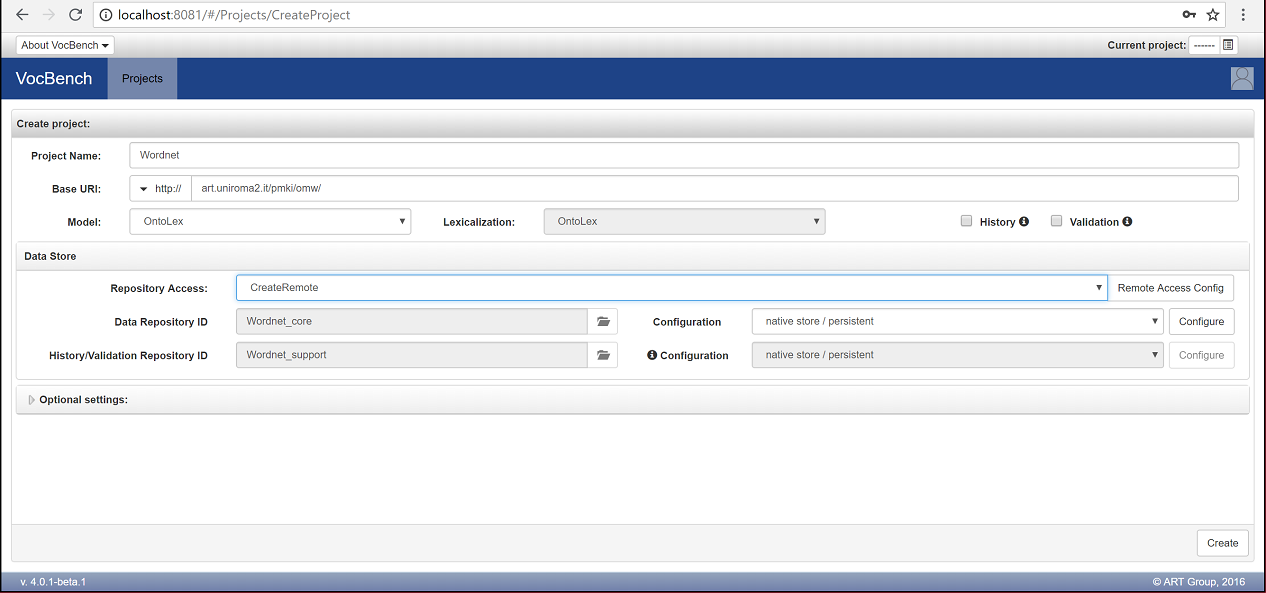
Fill the fields as in the following text and image below:
- Project Name: Wordnet
- Base URI: http://art.uniroma2.it/pmki/omw/ (it is important to keep the trailing "/" )
- Type: OntoLex
- Lexicalization: OntoLex
- History and Validation: disable both options
- Repository Access: set to CreateRemote
- Configuration (next to Data Repository ID): set to GraphDB Free (remote only)
The click on the "Remote Access Config" button, which leads to the following window:
By first create a new configuration, through the "Manage Config" button, which leads to the following window, where you have to insert the address where GDB is listening (we assume here that everything has been installed on the same machine, so that a "localhost" 127.0.0.1 address would work). Unless authorization credentials have been configured in GDB, no username and password is required.
By clicking on the + button the configuration will be saved, as in the following figure
After clicking on the "OK" button in the previous window, it is possible to select through the "Server URL" combobox the configuration previously setup, so that the window will look like this:
After clicking on "OK" on the previous windows, we come back to the Project Creation page:
We now setup the configuration for the core repository being created for storing the Wordnet data, by clicking on the first of the two "Configure" Buttons, related to the "Data Repository ID", and checking that one field, the "ruleset" one, has the value "empty", and leaving everything else as is.
We leave the other configuration unchanged (no need to click at all on the other "Configure" button), and finally click on the "Create" button at the bottom of the page, thus creating the project and the repository (core) on GraphDB.
c. Loading the Lexicon data
Before loading the data into VocBench, go to the Data and select the "Lex. Entry". Click on the gear button called "Settings". In the new window, select "Search Based"
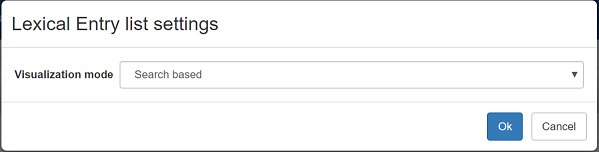
do the same action (press gear and then select "Search Based") on the concept tab.
Download the Wordnet lexicon RDF file and unzip it.
Select the newly created project, then go to the Global Data Management (top-right menu) and select "Load Data", as described here
Click on the "Browse" button next to the RDF file label and choose the Wordnet data file you have previously downloaded (wn_08_eng.rdf).
Leave all the other fields unchanged, as in the following figure:
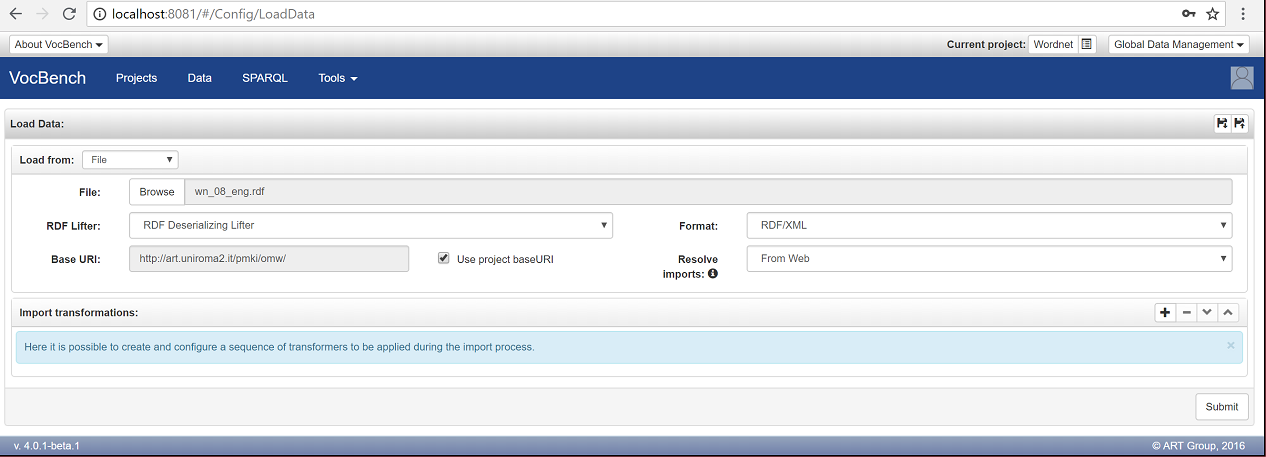
and then click on the "Submit" button.
The data loading process can take quite a few minutes (depending on the underlying hardware) as the hundreds of thousands of triples of Wordnet are loaded in the core repository
A confirmation message will inform you that the data has been loaded successfully.
Load pwn-concepts.rdf as well (to have also all concepts).
By clicking on the "Data" menu entry, it is possible to view the loaded lexicon.
The default tab in "Data" is "Lexicon". Select "Princeton Wordnet".
Open the "Lex.Entry" tab.
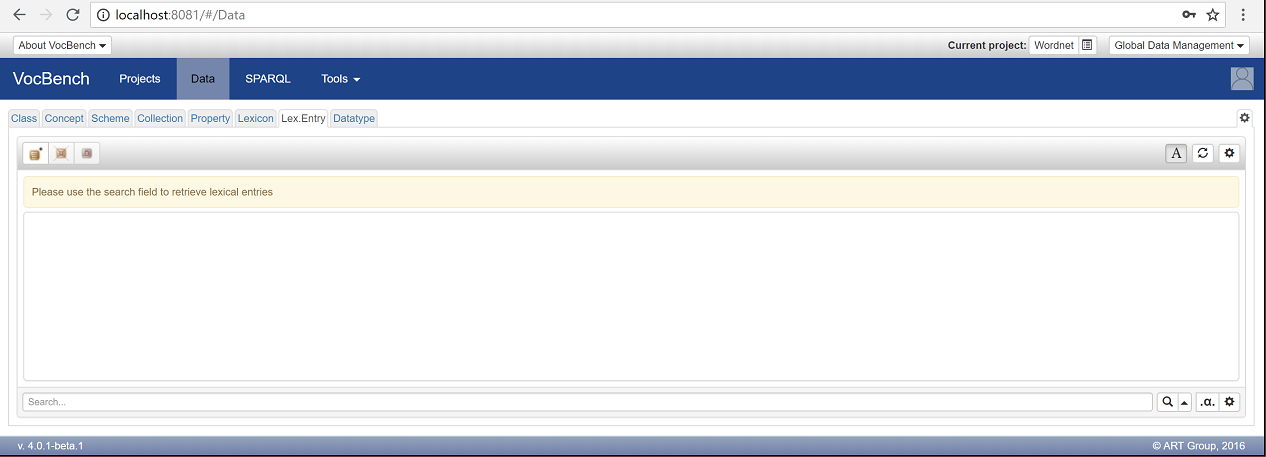
since the "Search Based" no Lexical Entry is shown. To see some Lexical Entries, search "dog"
In the lower part of the window, in the "Search" field write "dog" and press enter. After a couple of seconds, all Lexical Entries containing the word dog are returned:
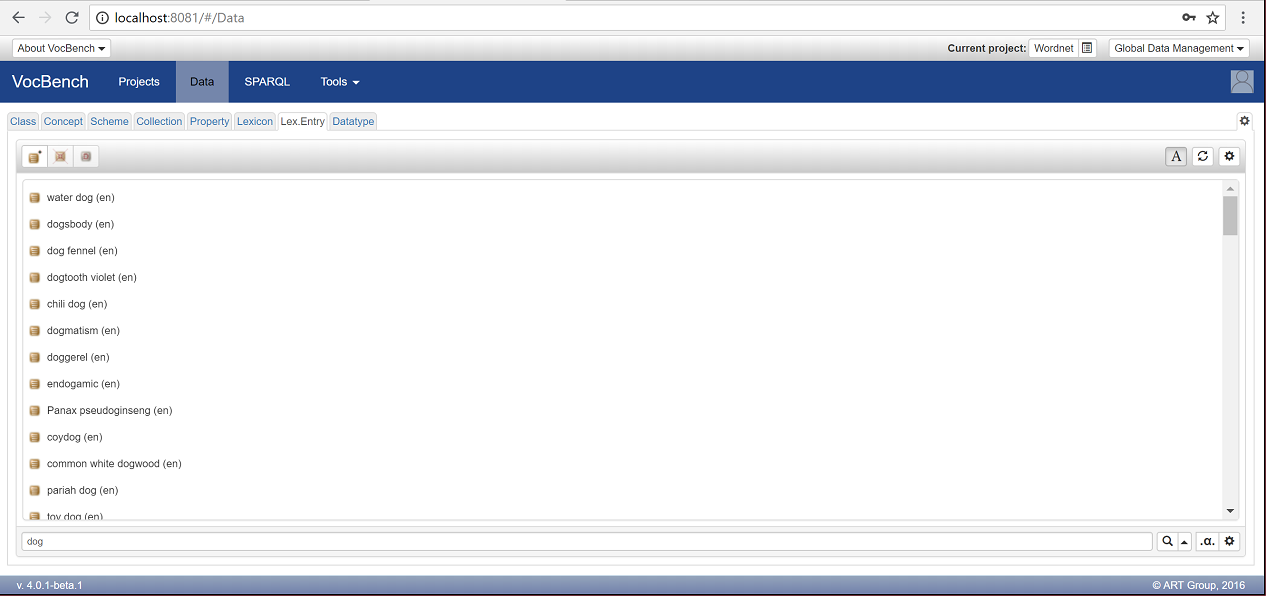
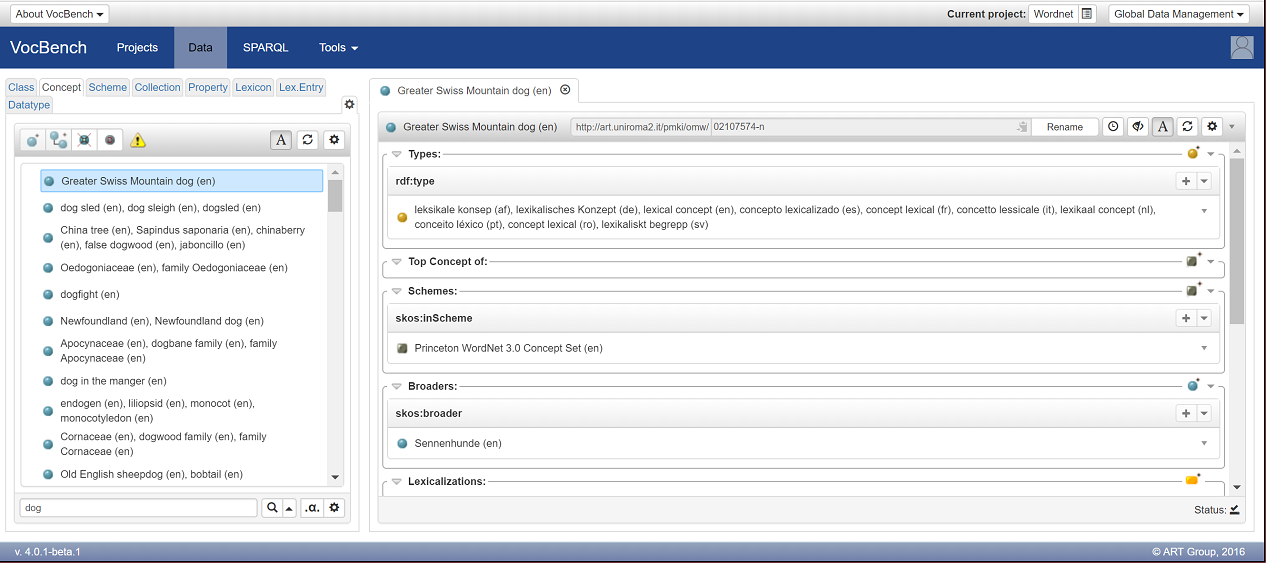
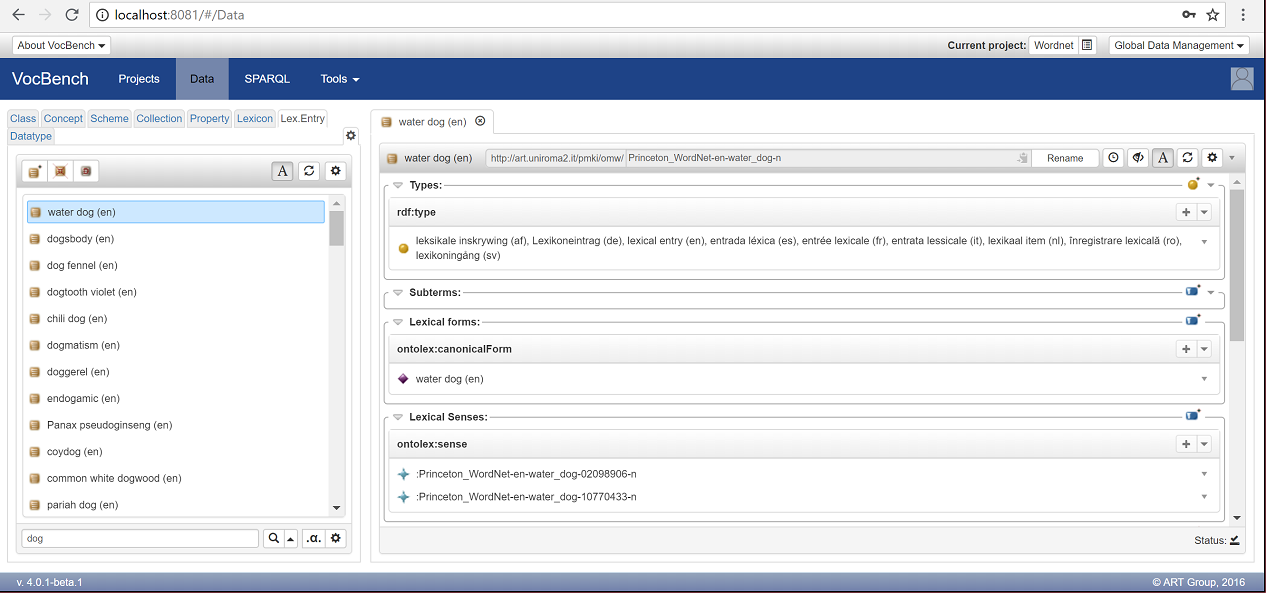
Click on the first entry, "water dog"to see all the information associated to it:
Open the "Concept" tab.
since the "Search Based" no concept is shown. To see some concepts, search "dog"
In the lower part of the window, in the "Search" field write "dog" and press enter. After a couple of seconds, all concepts containing the word dog are returned:
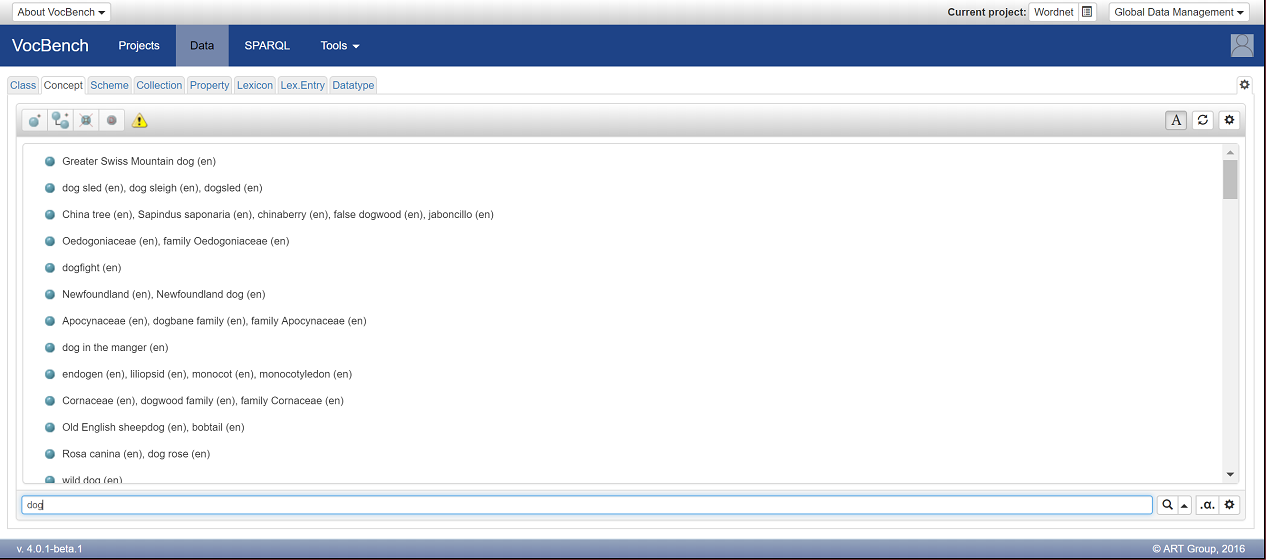
Click on the first entry, "Greater Swiss Mountain dog"to see all the information assocaited to it: